
无需参数访问!CMU用大模型自动优化视觉语言提示词 | CVPR’24
无需参数访问!CMU用大模型自动优化视觉语言提示词 | CVPR’24视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。
来自主题: AI技术研报
4612 点击 2024-11-05 15:28
 搜索
搜索
视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。

来自英伟达、CMU、UC伯克利等的全华人团队提出一个全新的人形机器人通用的全身控制器HOVER,仅用一个1.5M参数模型就可以控制人形机器人的身体。人形机器人的运动和操作之前只是外表看起来类人,现在有了HOVER,连底层运动逻辑都可以类人了!

Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。

虽然数据有限,但AI性能不会停滞不前,我们当前的算法还没有从我们拥有的数据中最大限度地提取信息,还有更多的推论、推断和其他过程我们可以应用到我们当前的数据上,以提供更多的价值。

「多智能体系统」是人工智能领域最热门的流行词之一,也是开源框架 MetaGPT 、 Autogen 等研究的焦点。 但是,多智能体系统就一定是完美的吗 近日,来自卡内基梅隆大学的副教授 Graham Neubig 在文章《Don't Sleep on Single-agent Systems》中强调了单智能体系统也不可忽视。

近日,来自 CMU 的 Catalyst Group 团队发布了一款 PyTorch 算子编译器 Mirage,用户无需编写任何 CUDA 和 Triton 代码就可以自动生成 GPU 内核,并取得更佳的性能。

Skild AI 是一家位于匹兹堡的初创公司,由两位前 CMU 教授创立,旨在打造具身智能的通用大脑。Skild 宣称其模型展示了无与伦比的泛化和涌现能力,并且有多于竞争对手 1000 倍的训练数据。

LLM数学水平不及小学生怎么办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。
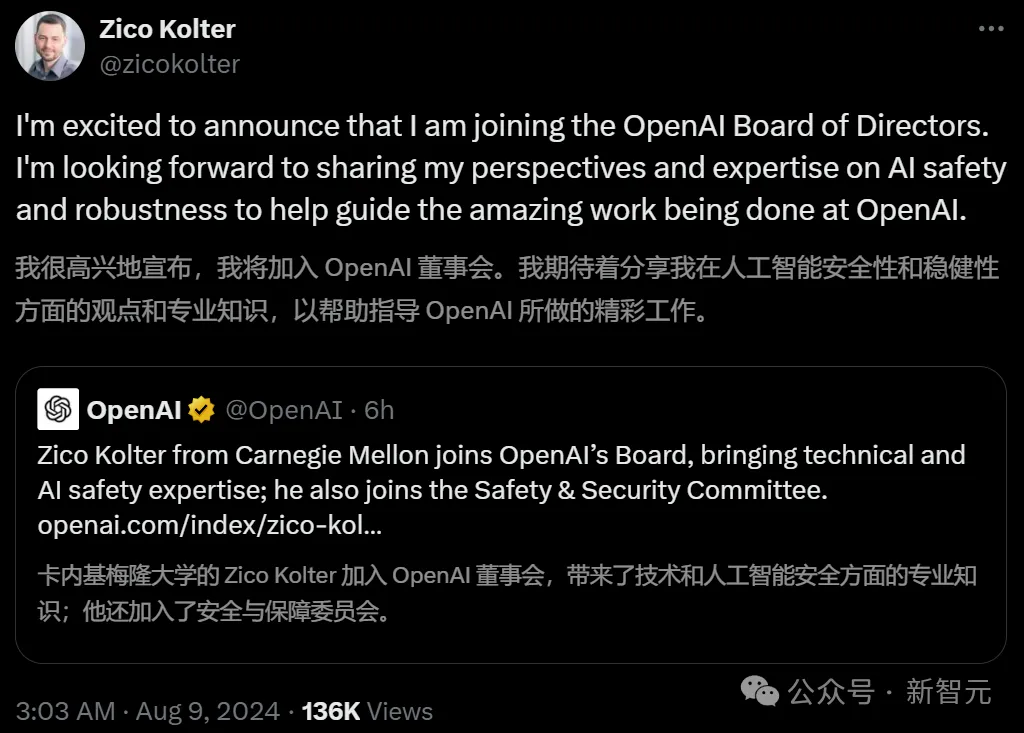
就在刚刚,CMU教授Zico Kolter正式宣布加入OpenAI董事会,并成为安全与安保委员会成员。OpenAI这是终于要在安全上下功夫了?

为了解决这个问题,一些研究尝试通过强大的 Teacher Model 生成训练数据,来增强 Student Model 在特定任务上的性能。然而,这种方法在成本、可扩展性和法律合规性方面仍面临诸多挑战。在无法持续获得高质量人类监督信号的情况下,如何持续迭代模型的能力,成为了亟待解决的问题。