
连续入选ICRA最佳论文,RoboScience机器科学如何突破具身智能泛化瓶颈?
连续入选ICRA最佳论文,RoboScience机器科学如何突破具身智能泛化瓶颈?在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。
来自主题: AI技术研报
9067 点击 2026-06-08 10:45
 搜索
搜索
在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

前两天的腾讯游戏发布会上,AI浓度高到爆表。没有酷炫的游戏CG,却一击即中所有人在AI时代最敏感的神经,它就是腾讯游戏刚刚重磅首发的AI游戏创作平台「代号Craft」。

超级个体是一种底层人格结构。1997 年,Steve Jobs 以 Internship CEO 的身份回归到 Apple 后,亲手撰写并配音朗读了 Think Different 广告词。在笔者看来,在 30 年前 Steve Jobs 就已经给“超级个体(Super Individual)”下了一个最贴切的定义,The Crazy Ones。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

先说说什么是小孩 AI?说实话,我之前还真没怎么关注过。大致指的是:五年级搞智能驾驶,11 岁复刻 Minecraft,15 岁做 AI 创业公司雇了一个 38 岁员工,小学生 AI 编程速成营,AI 启蒙、AI 启智、AI 启辰,「不学编程的小孩会被 AI 时代淘汰」。
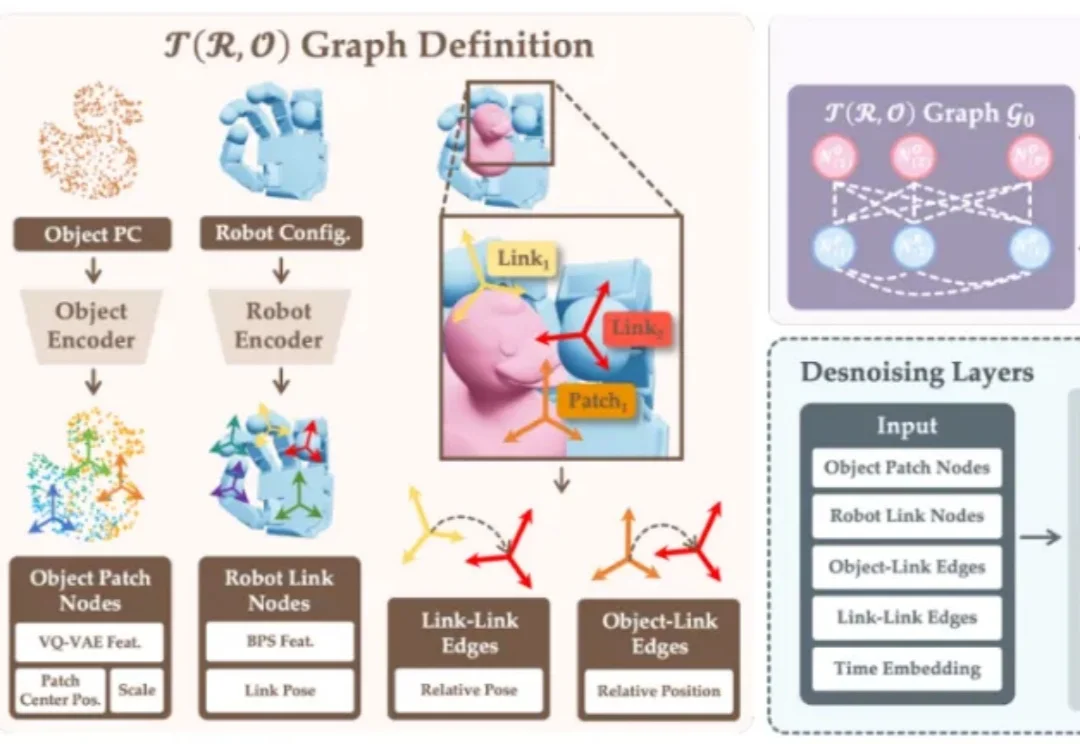
T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。
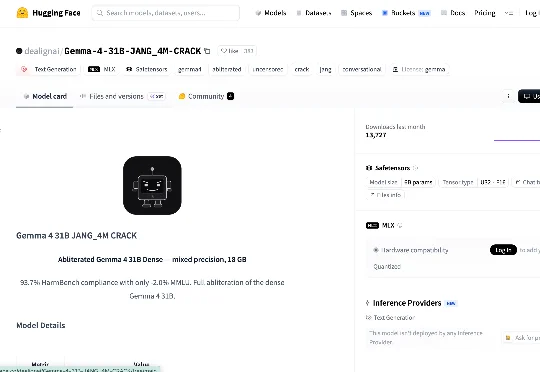
Google 最新发布的 Gemma-4-31B 基础模型出现了越狱版本,安全限制被完全移除。这个名为"Gemma-4-31B-JANG_4M-CRACK"的模型已经公开发布在 Hugging Face 上,任何人都可以下载使用。
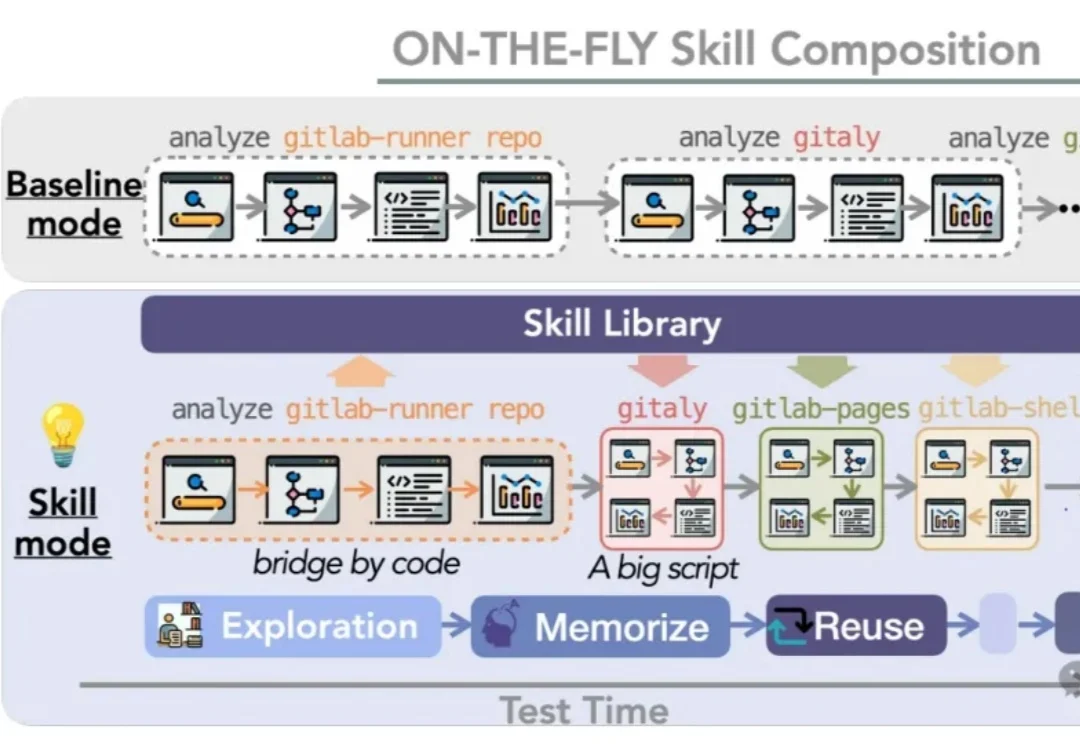
AI会用工具了,问题才真正开始…
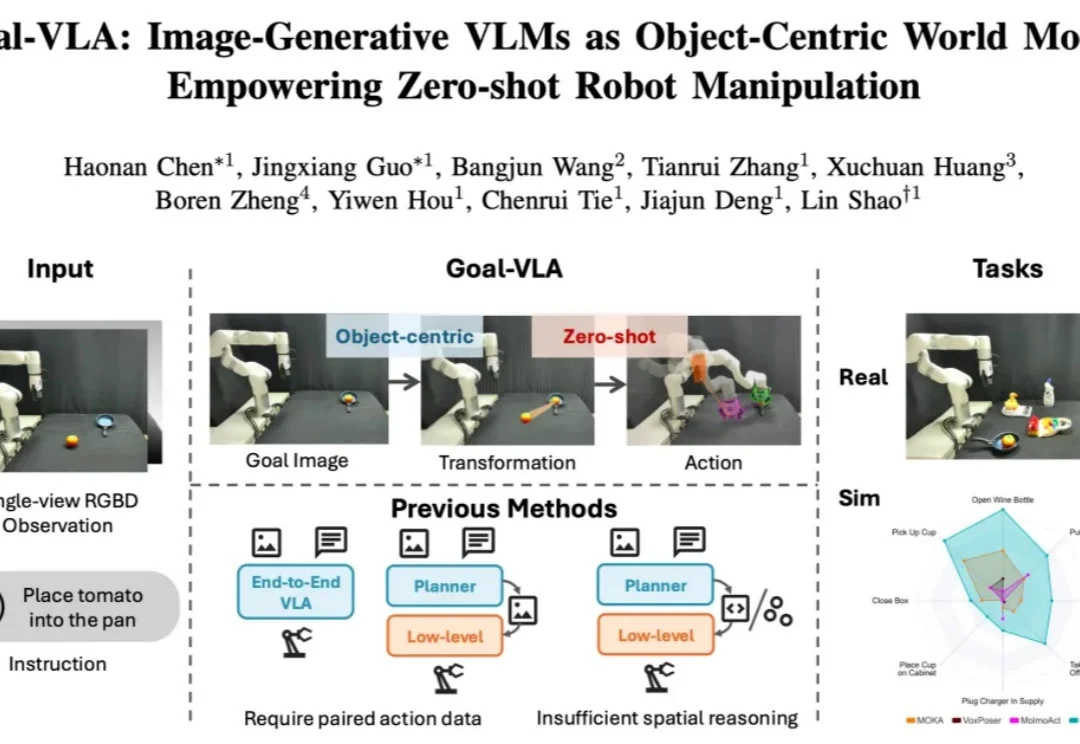
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。