
CVPR2026 | 鬼手想点谁就点谁?LaSM让GUI智能体把注意力「收回来」
CVPR2026 | 鬼手想点谁就点谁?LaSM让GUI智能体把注意力「收回来」如果把手机屏幕想象成一个舞台,GUI 智能体就是台下那个 “被授权动手” 的人:它能看懂屏幕上的按钮、输入框和弹窗,能按你的指令去点、去滑、去输入。
来自主题: AI技术研报
10268 点击 2026-04-07 14:28
如果把手机屏幕想象成一个舞台,GUI 智能体就是台下那个 “被授权动手” 的人:它能看懂屏幕上的按钮、输入框和弹窗,能按你的指令去点、去滑、去输入。
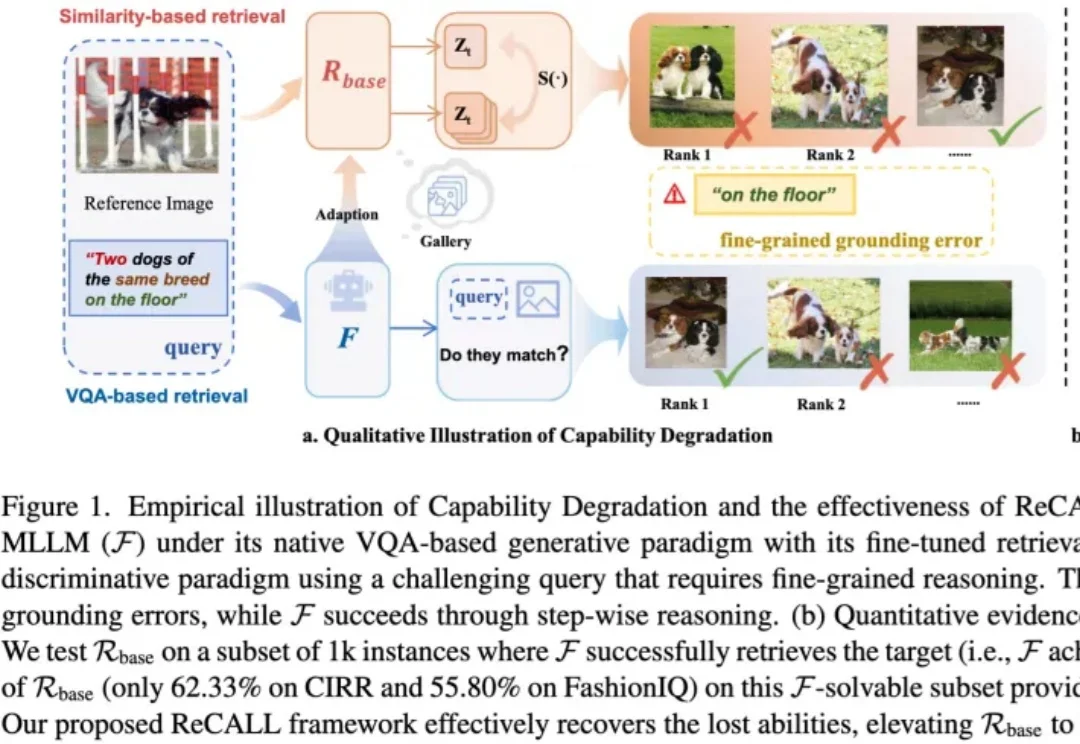
生成式模型当检索器大材小用效果还不好?

全球首个1毫秒级人体动作捕捉系统FlashCap,通过闪烁LED与事件相机结合,实现1000Hz超高帧率捕捉。无需昂贵设备或强光环境,低成本穿戴服即可精准捕捉极速动作。团队同步开源715万帧的FlashMotion数据集与多模态模型ResPose,显著提升运动分析精度,推动体育、VR与机器人领域迈向高动态智能新阶段。
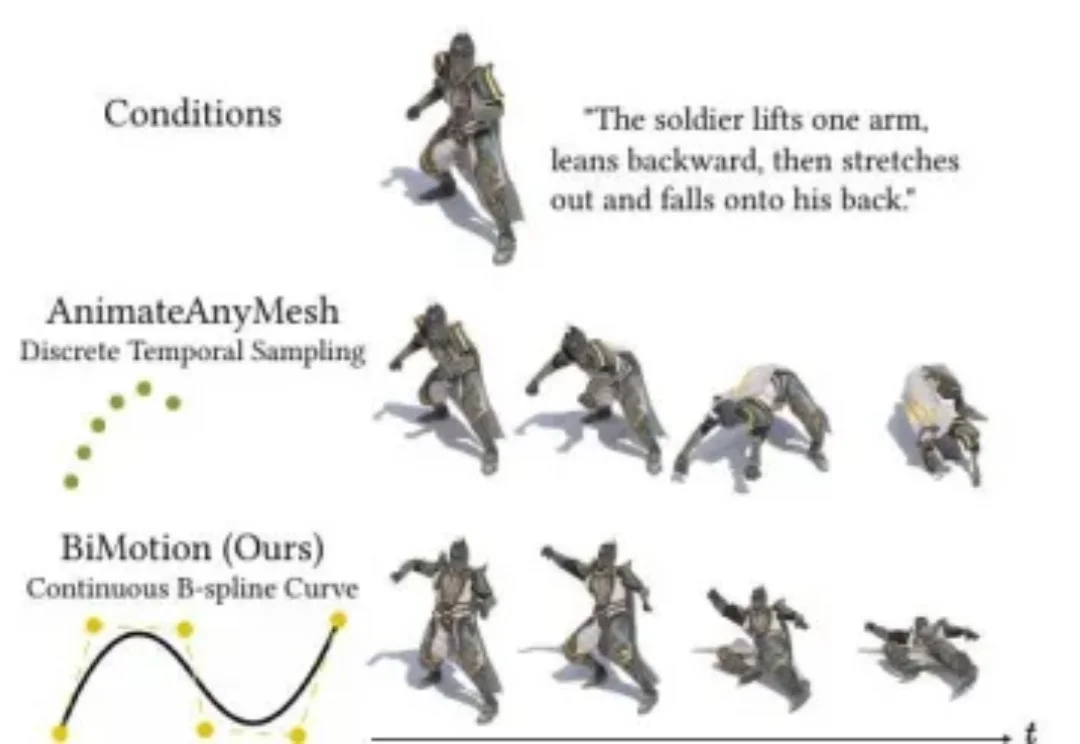
当你希望 AI 将 "士兵举起手臂,向后倾身,然后身体向前扑倒" 这段文字转化为一段 3D 角色动画,现有大多数方法给出的答案是:一段摇摇晃晃、语义残缺的短片段。这并非模型能力不足,问题的根源在于将运动表达为逐帧离散序列这一根本性的设计决策。

Mirage(原 Captions)宣布获得 7500 万美元 融资,由 General Catalyst 旗下 Customer Value Fund(CVF)提供。这类资金的逻辑,与传统 VC 明显不同,它更关注已经被验证的增长模型与单位经济,而不是单纯押注未来。

视频编辑应用 Captions 的开发商 Mirage 已从 General Catalyst 的客户价值基金(CVF)筹集了 7500 万美元的增长融资。
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大