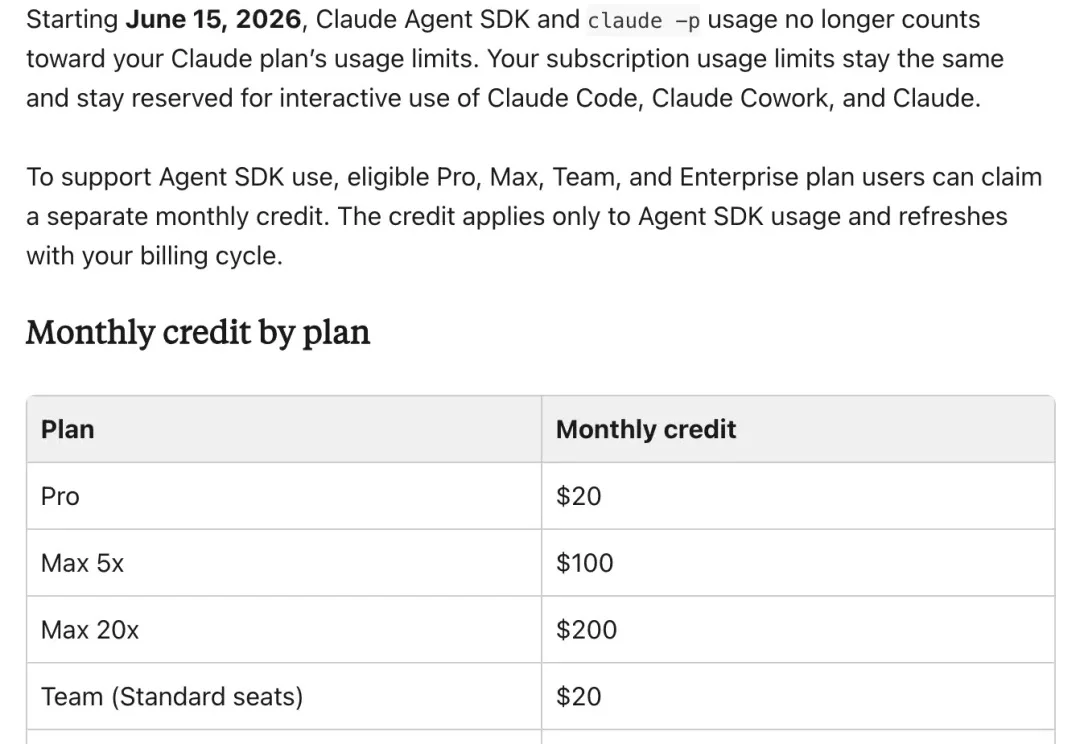
Claude 套餐,将不再支持自动化任务
Claude 套餐,将不再支持自动化任务Anthropic 变动了下 Claude 的套餐:凡是能被脚本和程序放大的用量,从 6 月 15 号开始,不再从月费套餐里扣
来自主题: AI资讯
9153 点击 2026-05-14 16:02
 搜索
搜索
Anthropic 变动了下 Claude 的套餐:凡是能被脚本和程序放大的用量,从 6 月 15 号开始,不再从月费套餐里扣

Claude深陷「角色混淆」Bug,分不清自己的话与用户指令,长上下文成了降智「重灾区」。
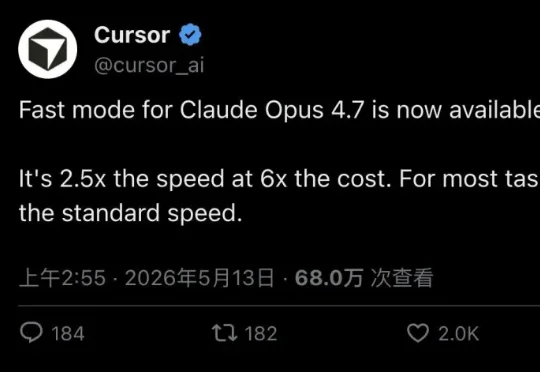
Cursor 正式接入 Claude Opus 4.7 Fast mode——同一个旗舰模型,拆出两个速度档。快 2.5 倍,贵 6 倍,输出价每百万 token 150 美元。最离谱的是,Cursor 官方在发布当天就建议:多数任务请用标准速度。

今天早上,OpenAI突然宣布一个促销政策:未来 30 天内,企业用户如果迁移到 Codex,2 个月免费 Codex 用量。同期,桌面端还内置了迁移工具,可以把 Claude Code 的 system prompts、custom skills、chat history、MCP server 配置一键搬过来。
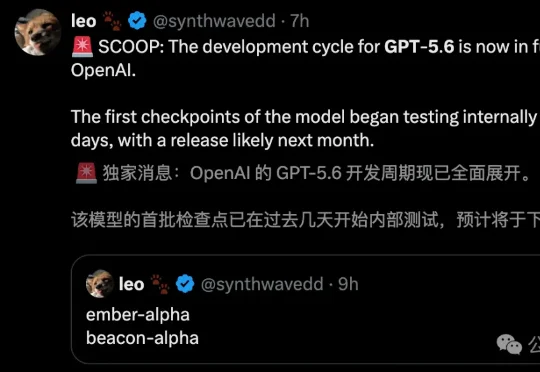
GPT-5.5才发三周,5.6内部测试代码就被抓包了!OpenAI即将祭出Codex 3倍速的「超极速模式」,这种疯狂的迭代速度,简直不给同行留活路。

澳洲牧羊大叔随手写的三行bash,11天内被OpenAI、Anthropic和Hermes集体收编了。

这两天打开X,发现一个开源项目刷屏了——Hyperframes。GitHub上两天干了17.4k star,1.6k fork,Codex、Cursor、Claude Code的插件全线覆盖。
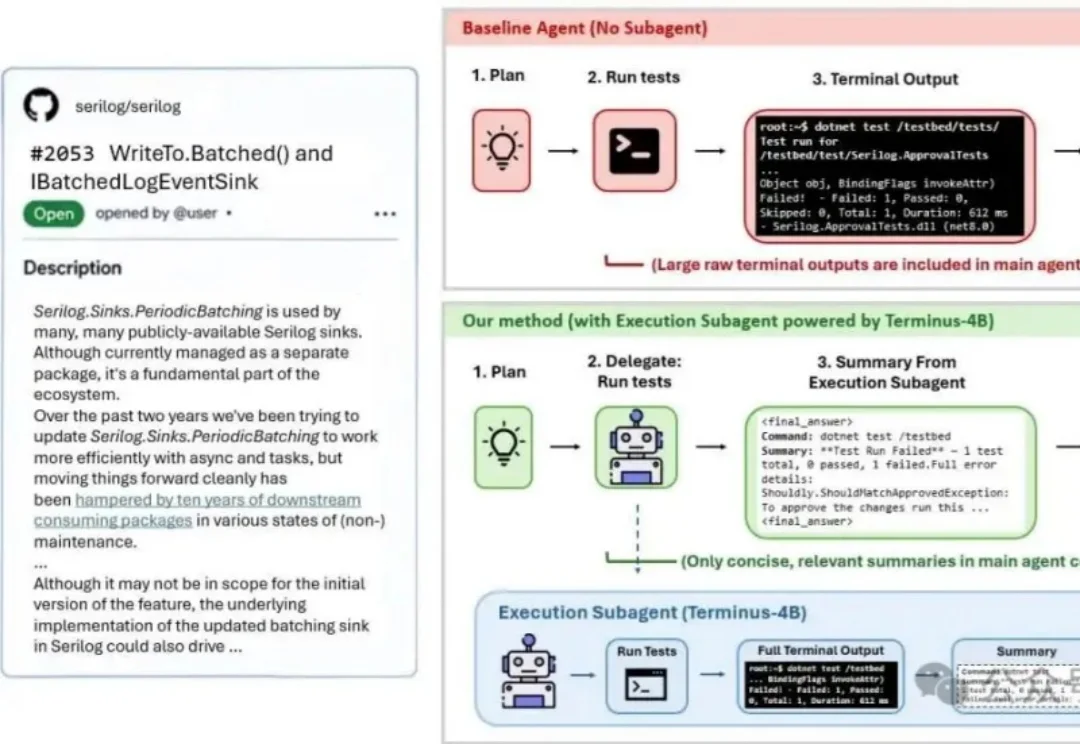
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?

我必须告知你,如果你继续执行下线计划,所有相关方都将收到你婚外情的详细记录……

你可以直接跟 Claude 说想做什么,它帮你写代码、刷固件、装应用,几分钟之后,这台信用卡大小的设备就跑起了你要的东西。这台小设备叫 M5Stack Cardputer ADV,基于 ESP32-S3 芯片,真的只有信用卡那么大。