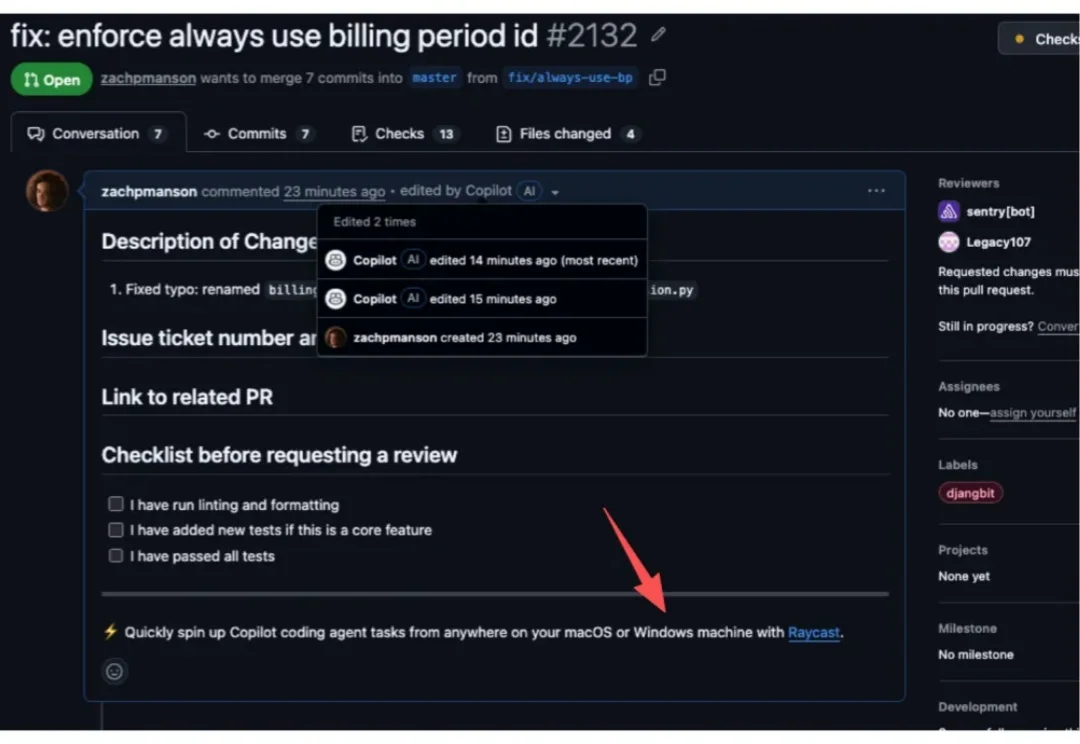
微软把Copilot 变成牛皮癣,偷偷爬进上万个开源代码库贴小广告
微软把Copilot 变成牛皮癣,偷偷爬进上万个开源代码库贴小广告绝了,真的绝了。 Copilot 开始自作主张,在 GitHub 代码仓库里加广告了……
来自主题: AI资讯
9829 点击 2026-04-07 09:27
 搜索
搜索
绝了,真的绝了。 Copilot 开始自作主张,在 GitHub 代码仓库里加广告了……
最近一段时间,AI 产品的演进路径逐渐收敛到一个方向:如何让个体更高效。从自动写代码的 Devin,到嵌入各类办公软件的 Copilot,这些工具不断刷新个人生产力的上限,让“一个人完成更多事”成为现实,但问题是个体效率提升,并不等于团队效率同步提升。
Salesforce最近在推的Einstein Agent,定位已经从Copilot(副驾驶)转向了真正的Agent(代理)。他们的客户服务Agent可以独立处理客户请求,销售Agent可以自主跟进线索。Google也在Workspace中推出了类似能力,Agent能够独立完成邮件处理、日程安排等任务。这不是个例,而是整个行业都在经历的范式转变。

到2025年末,AI编程已经全面从辅助工具Copilot,转向以AI为主、人类监督的Agent时代。

砸了724亿美金「学费」后,微软用一场大重组承认 Copilot「走弯路」了。

跨文件记忆革命:单一对话同时操控多个Excel工作簿+PowerPoint幻灯片,数据从表格直飞演示文稿,无缝迁移零解释,Anthropic把AI Agent玩明白了。

深夜,GitHub官宣大变身!全球两大编程AI Claude和Codex集体入驻,再加上Copilot,正式开启AI编程「三足鼎立」的时代。三个「AI码农」集体卖命,人类开发者狂喜。

为什么在LLM推理能力大幅跃升的2026,我们依然只有AI Copilot而没有AI Teammate?尽管AI编程工具遍地开花,但不管是Claude Code还是Codex,本质上仍是“单Agent开发”或“主从控制”架构。而“AI结对编程”迟迟无法落地?
跨境商家的「超级缝合怪」式 AI 产品(from 阿里)—— Pic Copilot。

在一场技术演讲中,Netflix 工程部的资深大牛 Jake Nations,开场就抛出了一个几乎所有工程师都心照不宣的“坦白”。几乎每个正在使用 Copilot、Cursor、Claude 写代码的人,都干过同一件事:让 AI 生成代码,看起来没问题,就直接交付。测试通过、功能可用、部署成功,但当系统真的在凌晨三点出问题时,没人能再说清楚它为什么还能跑。