让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
来自主题: AI技术研报
8693 点击 2025-08-13 11:27
 搜索
搜索
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
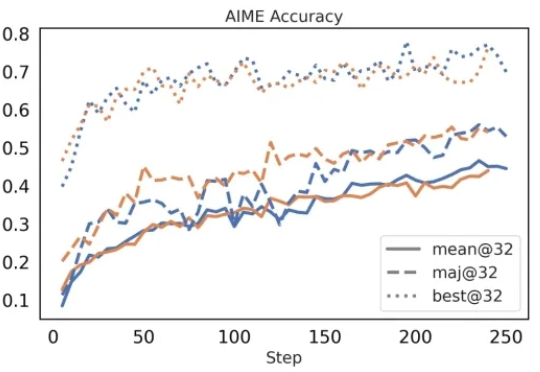
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。

一个超越DeepSeek GRPO的关键RL算法出现了!这个算法名为DAPO,字节、清华AIR联合实验室SIA Lab出品,现已开源。禹棋赢,01年生,本科毕业于哈工大,直博进入清华AIR,目前博士三年级在读。去年年中,他以研究实习生的身份加入字节首次推出的「Top Seed人才计划」。

DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。