

X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习
X上63万人围观的Traning-Free GRPO:把GRPO搬进上下文空间学习年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
来自主题: AI技术研报
6742 点击 2025-10-23 11:41
年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
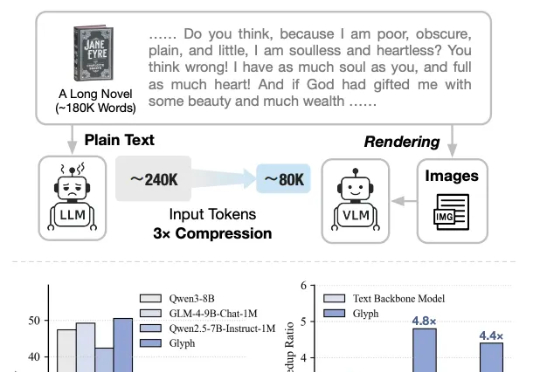
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:

OpenAI前研究副总裁Liam Fedus与DeepMind材料科学领军者Ekin Cubuk共创Periodic Labs,以一轮高达3亿美元的种子融资走出隐身模式,震惊硅谷。然而,曾给出祝福的前东家OpenAI,并未参与本轮投资。
在出海营销的赛道上,AI 已经成了人人必提的“标配”。在这股AI狂潮中,有一家成立仅一年的公司,悄悄跑出一条“反直觉”的增长曲线 —— DeepLink,这家创立于2024年的AI网红营销公司,已获得阿尔法、险峰长青、金沙江联合等多家一线机构投资,ARR突破500万美元。

DeepSeek最新开源的模型,已经被硅谷夸疯了!
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被

AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。
“我有两张券,分别为满1000减140、满2000减280,我看中商品的价格分别为……分两次结算怎么凑单最划算?”双11开启后,在社交平台上,有人向Deepseek抛出这个问题。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。