
DeepSeek V4逼近,美国慌了!被曝绕过英伟达优先国内,绝密参数已泄露
DeepSeek V4逼近,美国慌了!被曝绕过英伟达优先国内,绝密参数已泄露最近,炸裂消息一个接一个。首先,DeepSeek V4将在一周内上线。第二,它跳过英伟达,把访问权限首先给了某国内芯片厂商。另外,Anthropic因为蒸馏事件,也被群嘲了。
来自主题: AI资讯
10125 点击 2026-02-26 20:20
 搜索
搜索
最近,炸裂消息一个接一个。首先,DeepSeek V4将在一周内上线。第二,它跳过英伟达,把访问权限首先给了某国内芯片厂商。另外,Anthropic因为蒸馏事件,也被群嘲了。

科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。

DeepSeek员工节后一上班,美国AI圈又要抖三抖了(doge)。就从十几个小时前开始,DeepSeek的GitHub仓库突然一阵猛更新,Merge了一堆PR:维护者主要是mowentian——DeepSeekMoE等论文的署名作者之一Huang Panpan。他这一干活不要紧,大洋彼岸“V4来了???”的紧张神经,又被瞬间挑了起来。

今天,美国大模型独角兽Anthropic连续发布多则推文、博客,指控DeepSeek、月之暗面和MiniMax三家中国AI实验室,正对Claude进行“工业级规模的蒸馏攻击”。
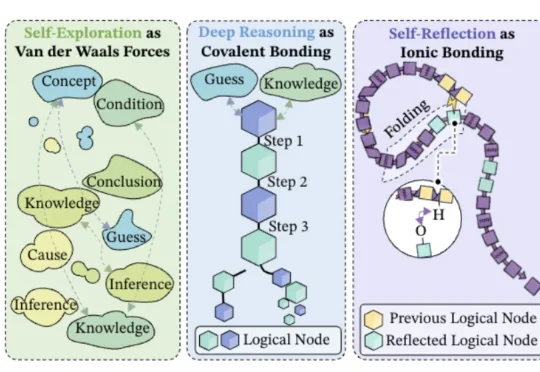
字节Seed都开始用化学思想搞大模型了——深度推理是共价键、自我反思是氢键、自我探索是范德华力?!

刚刚, Anthropic 发推称,DeepSeek、Moonshot AI和MiniMax三家国内的 AI 公司对Claude进行大规模的蒸馏攻击。OK, A 社你真的很讨厌中国公司了。简单说就是:这三家公司用大量假账号,疯狂地向 Claude 提问,然后拿 Claude 的回答去训练自己的模型。

机器之心编译 如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。 自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从
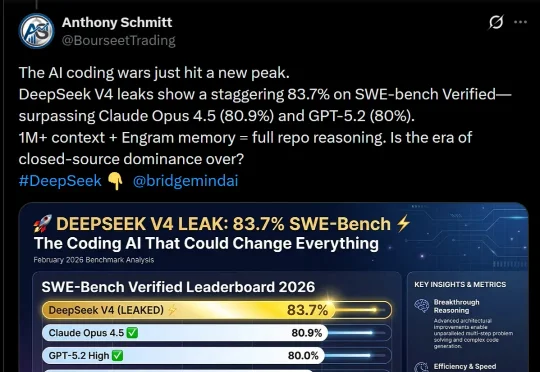
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!

确认了!DeepSeek昨晚官宣网页版、APP更新,支持100k token上下文。如今,全网都在蹲DeepSeek V4了。