

在DeepSearch中用DeepSeek-R1来做动作决策会更好么?
在DeepSearch中用DeepSeek-R1来做动作决策会更好么?众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?
来自主题: AI技术研报
5790 点击 2025-04-02 14:40
众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?
4月1日,途牛旅游网自主研发的“AI助手小牛”旅游应用Agent正式上线途牛旅游APP、“AI助手小牛”小程序。“AI助手小牛”结合旅行垂直应用场景与开源大模型(DeepSeek、通义千问),实现了机票、酒店、火车票快捷查询、预订服务,能够为用户提供智能、专业的“0搭售"旅游服务方案。
借助新版DeepSeek-V3,任何人现在可以一次性创建任何应用或游戏了——
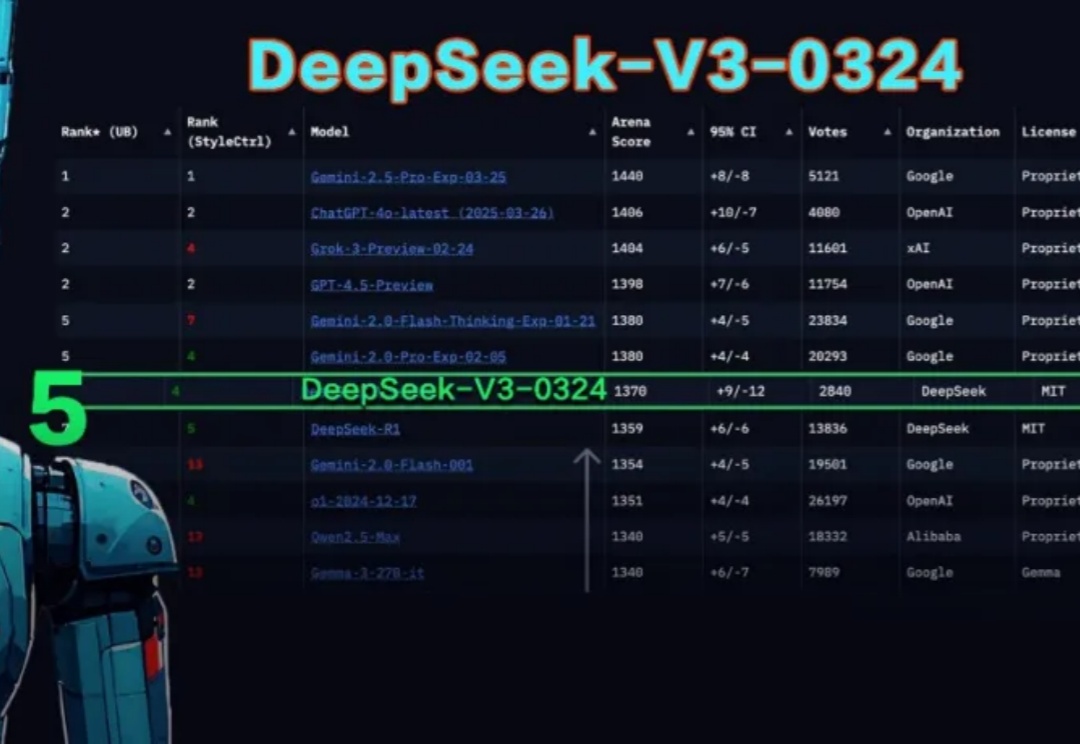
DeepSeek又卷起来了!上周刚出的DeepSeek-V3-0324在大模型竞技场排名中,打败了自己的DeepSeek-R1,成为开源AI至尊。
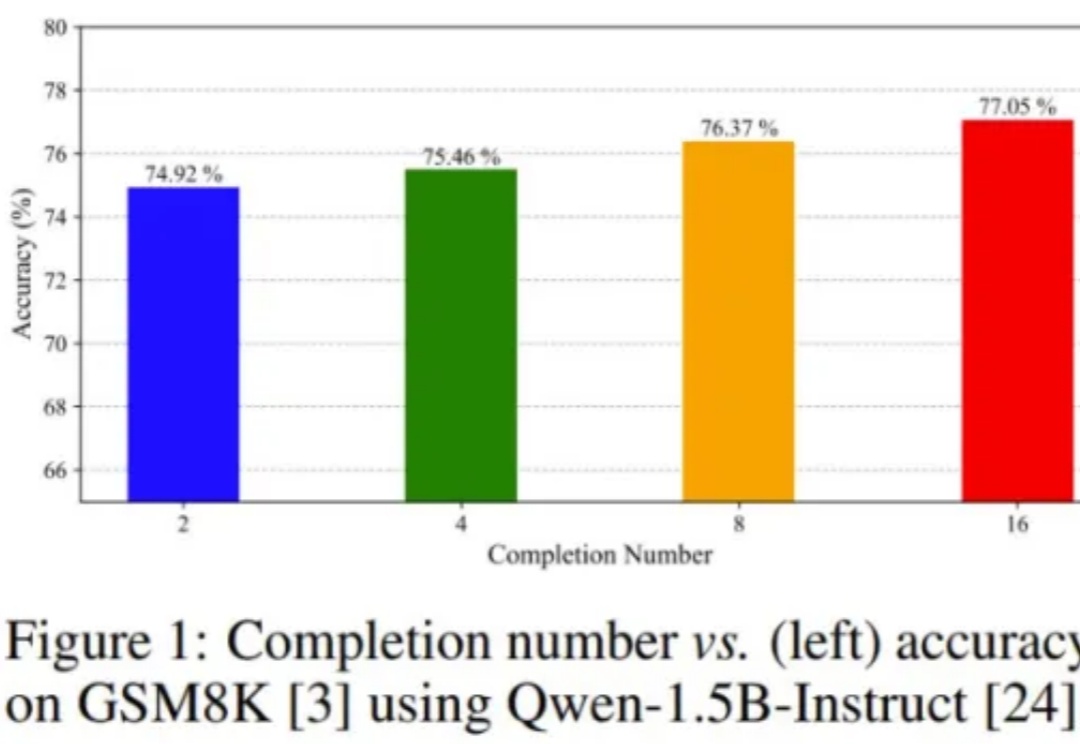
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
刚刚,百度文小言全面升级了。

一夜之间,OpenAI更新三大动向,开源、融资、用户暴增。第一,将开源一个具备推理能力的大语言模型,包含参数权重那种。上一次这样开源还是6年前推出GPT-2。

DeepSeek的出圈,不仅引爆了全社会对于AI的大讨论,更重要的是激发各界人士从观望者转变为参与者,掀起了一波真实的人工智能落地潮。在孕育了AI的互联网生态中,AI引起的变化会首当其冲,且影响更彻底。广告作为互联网生态最主要的商业模式,更是当前AI技术应用的主战场。

DeepSeek要开放融资了?
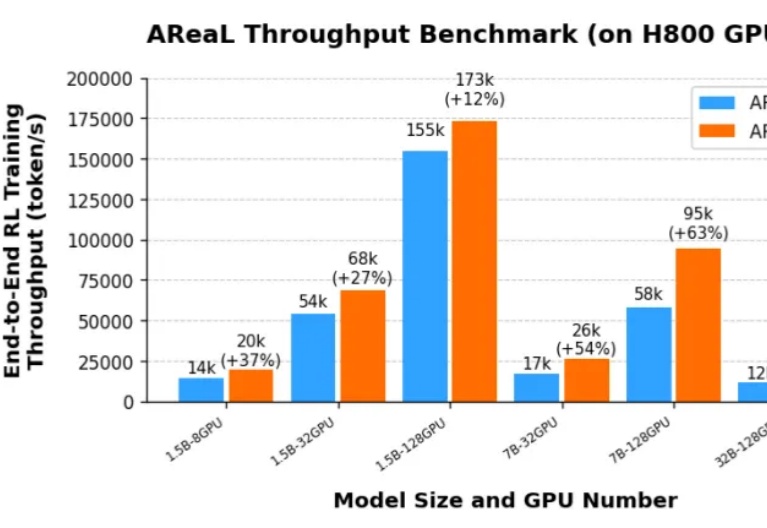
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高: