
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成
告别多奖励跷跷板:Flow-OPD将多教师OPD带入图像生成今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
来自主题: AI技术研报
6786 点击 2026-05-26 10:07
 搜索
搜索
今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。
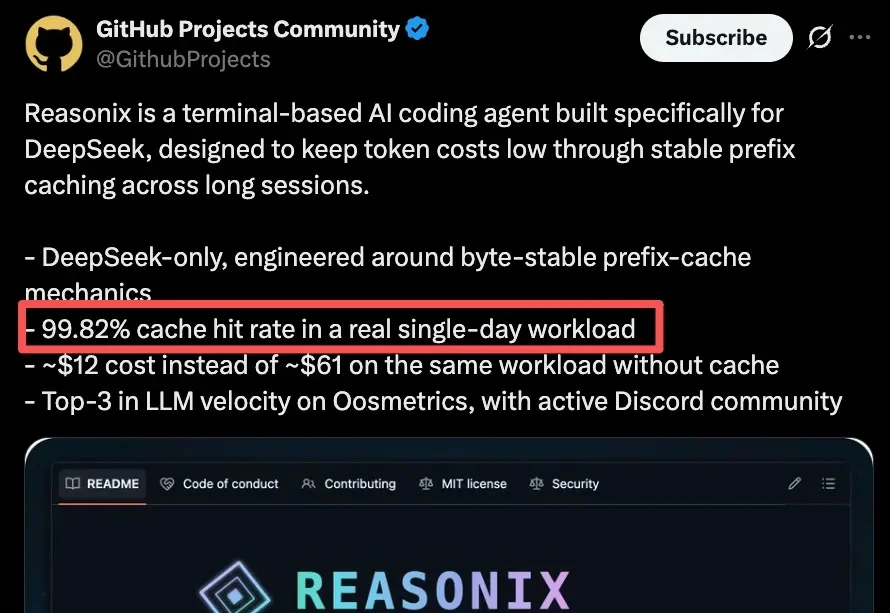
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

DeepSeek正用开源、降价和底层架构创新,重画AI硬件生态的成本曲线,把目标指向十万亿美元产业与AGI的星辰大海。
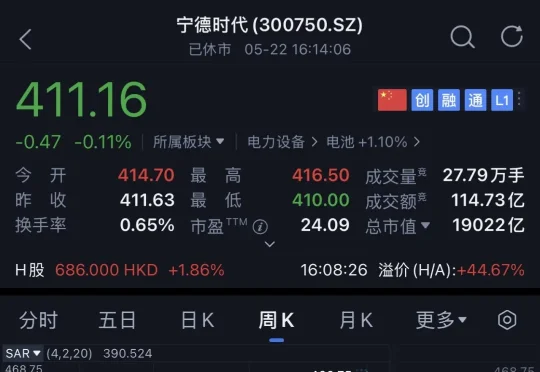
据The Information昨晚报道,全球动力电池市场龙头宁德时代拟入局DeepSeek首轮融资。这是宁德时代在AI领域被曝出的最新布局。就在刚刚过去的一个半月内,宁德时代官宣斥资105亿元加码AI算电协同赛道,电力、算力、储能、AI一体化全产业链布局全面落地。

说实话,我原本以为 DeepSeek 的限时优惠会在5月31日结束。毕竟降价75%,打了2.5折,怎么看都像是一波限时引流。5月22号晚上,DeepSeek发了个通知,我看了两遍才确认没看错——DeepSeek V4-Pro永久降价!

,今天,据彭博社报道,DeepSeek正在进行一轮高达约700亿元人民币(约合100亿美元)的融资。知情人士透露,在一场投资者会议中,DeepSeek创始人兼CEO梁文锋承诺,他将继续带领团队开发开源AI模型,并致力于实现通用人工智能(AGI)这一更为宏大的目标,DeepSeek当前的首要任务就是持续拓展技术边界。

DeepSeek Code要来了。
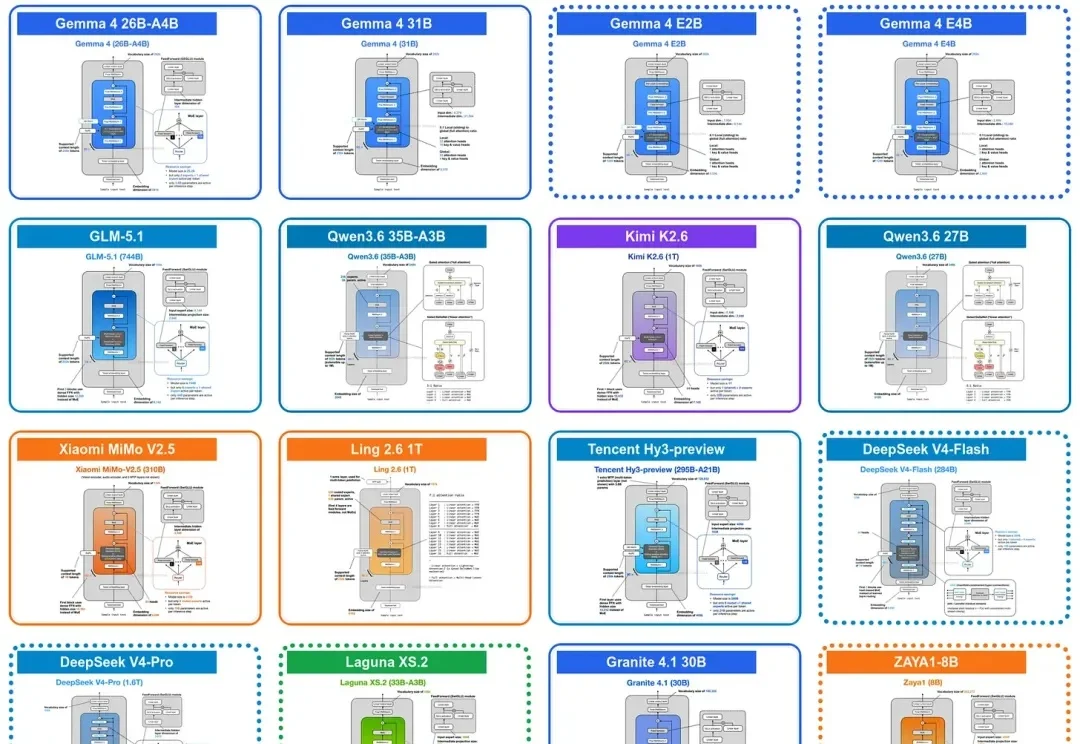
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
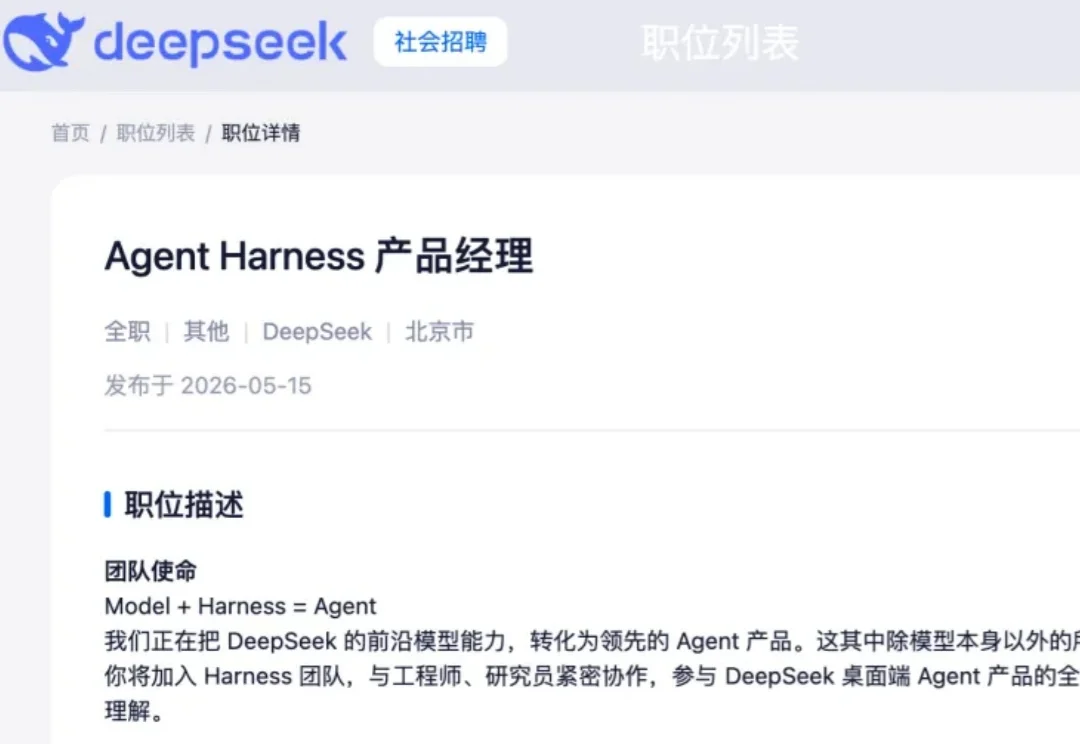
DeepSeek最新热招岗位已上线:Agent Harness产品经理。