
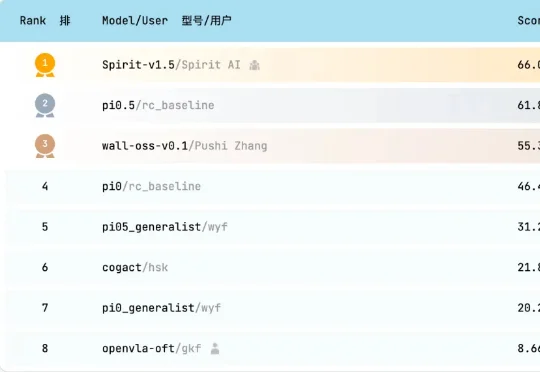
具身智能DeepSeek时刻!千寻智能模型开源即登顶全球榜单
具身智能DeepSeek时刻!千寻智能模型开源即登顶全球榜单全球榜单中唯一成功率超过50%的模型。今日,千寻智能正式开源自研VLA基础模型Spirit v1.5,就在前一天,该模型在全球具身智能模型评测平台RoboChallenge上,综合评测斩获第一。
来自主题: AI资讯
9197 点击 2026-01-12 09:27
全球榜单中唯一成功率超过50%的模型。今日,千寻智能正式开源自研VLA基础模型Spirit v1.5,就在前一天,该模型在全球具身智能模型评测平台RoboChallenge上,综合评测斩获第一。

前几天元旦,DeepSeek 又激发了「假期更新」 Buff,梁文锋署名新论文刷屏 AI 圈,就在大家都在等待 V4 的发布时,我发现有一群人早就在 DeepSeek 里找到了新乐子:自制「橙光游戏」。
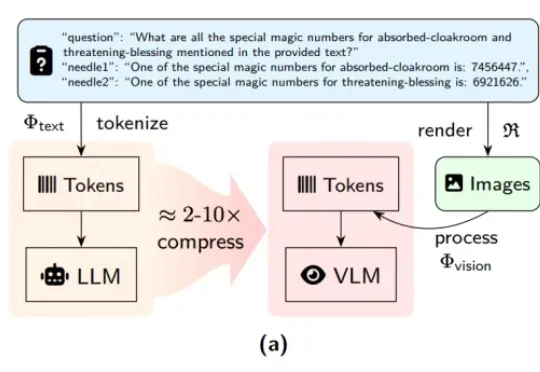
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注。为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ——VTCBench。

今天受邀,参加了一个非常有趣的活动,现场人真的爆满了,很多人都是从外地特意赶过来的。 这个活动,叫AGI-NEXT。 主要是几个演讲的嘉宾,过于重磅了。 开源四巨头除了DeepSeek没来,智谱的唐杰老师、Kimi的杨植麟、Qwen的林俊旸,齐聚一堂。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
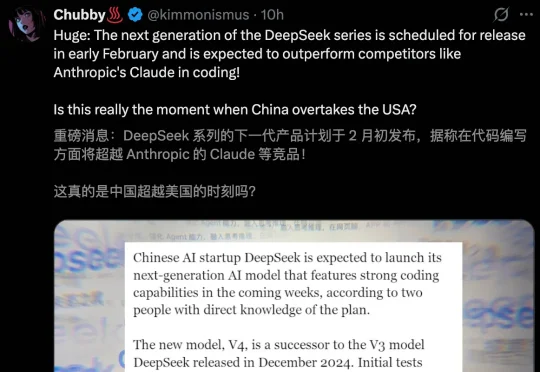
Information爆料称,DeepSeek将计划在2月中旬,也正是春节前后,正式发布下一代V4模型。据称,DeepSeek V4编程实力可以赶超Claude、GPT系列等顶尖闭源模型。
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!

CES巨幕上,老黄的PPT已成中国AI的「封神榜」。DeepSeek与Kimi位列C位之时,算力新时代已至。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
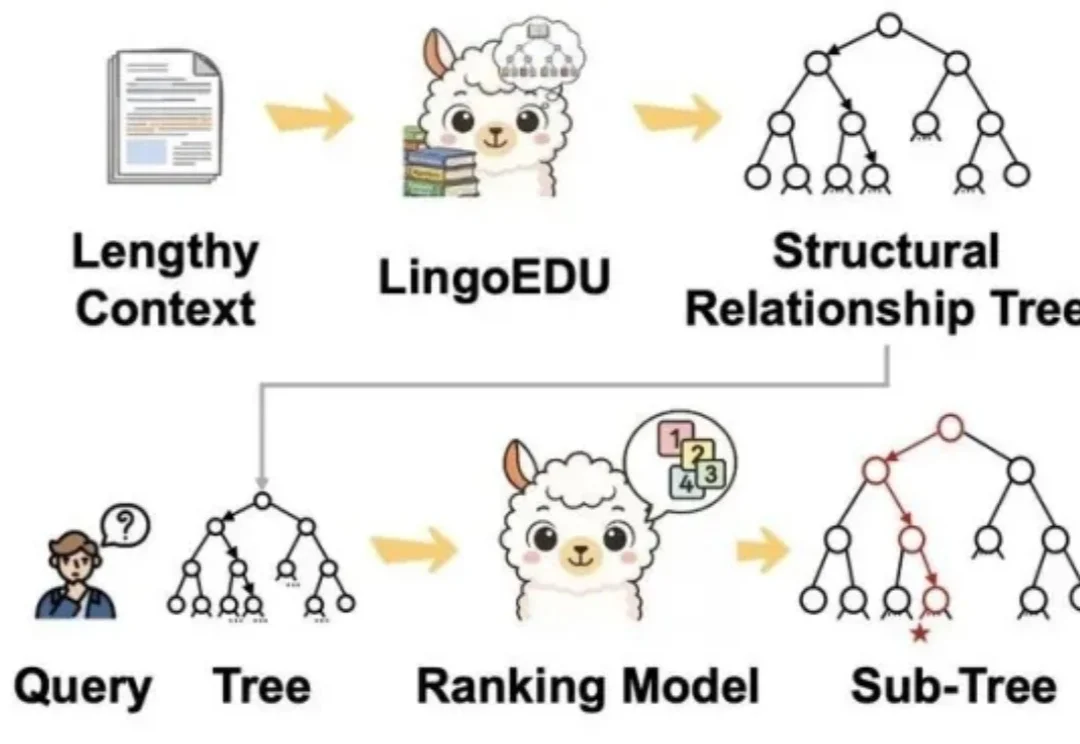
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!