Meta超级智能实验室新论文陷争议!被指忽略大量前人研究
Meta超级智能实验室新论文陷争议!被指忽略大量前人研究Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。
来自主题: AI技术研报
8299 点击 2025-09-12 11:55
 搜索
搜索
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。
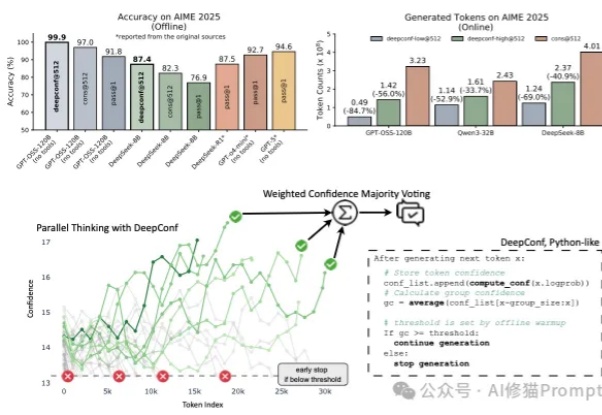
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。

AI作画、生视频,可以「自己救自己」了?! 当大家还在为CFG(无分类器引导)的参数搞到头秃,却依然得到一堆“塑料感”废片而发愁时,来自清华大学、阿里巴巴AMAP(高德地图)、中国科学院自动化研究所的研究团队,推出全新方法S²-Guidance (Stochastic Self-Guidance)。
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。

近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。

游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
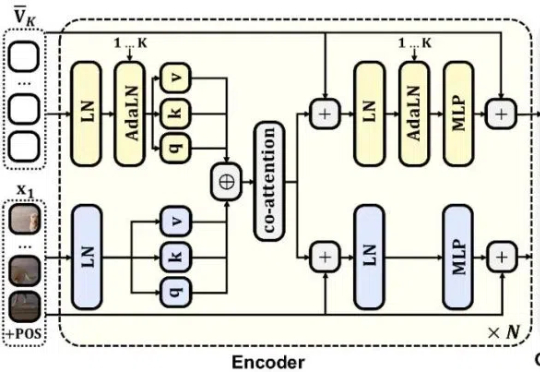
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
近日,以色列宣布与以色列AI“数字化身”制作平台eSelf、以色列最大的K12教科书出版商CET(Center for Educational Technology)合作,在全国范围内铺开AI辅导。