
网传DeepSeek R1更容易被越狱?这有个入选顶会的防御框架SelfDefend
网传DeepSeek R1更容易被越狱?这有个入选顶会的防御框架SelfDefend近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
来自主题: AI技术研报
5749 点击 2025-02-11 14:48
 搜索
搜索
近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
一位“出海老兵”的自救。

代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!

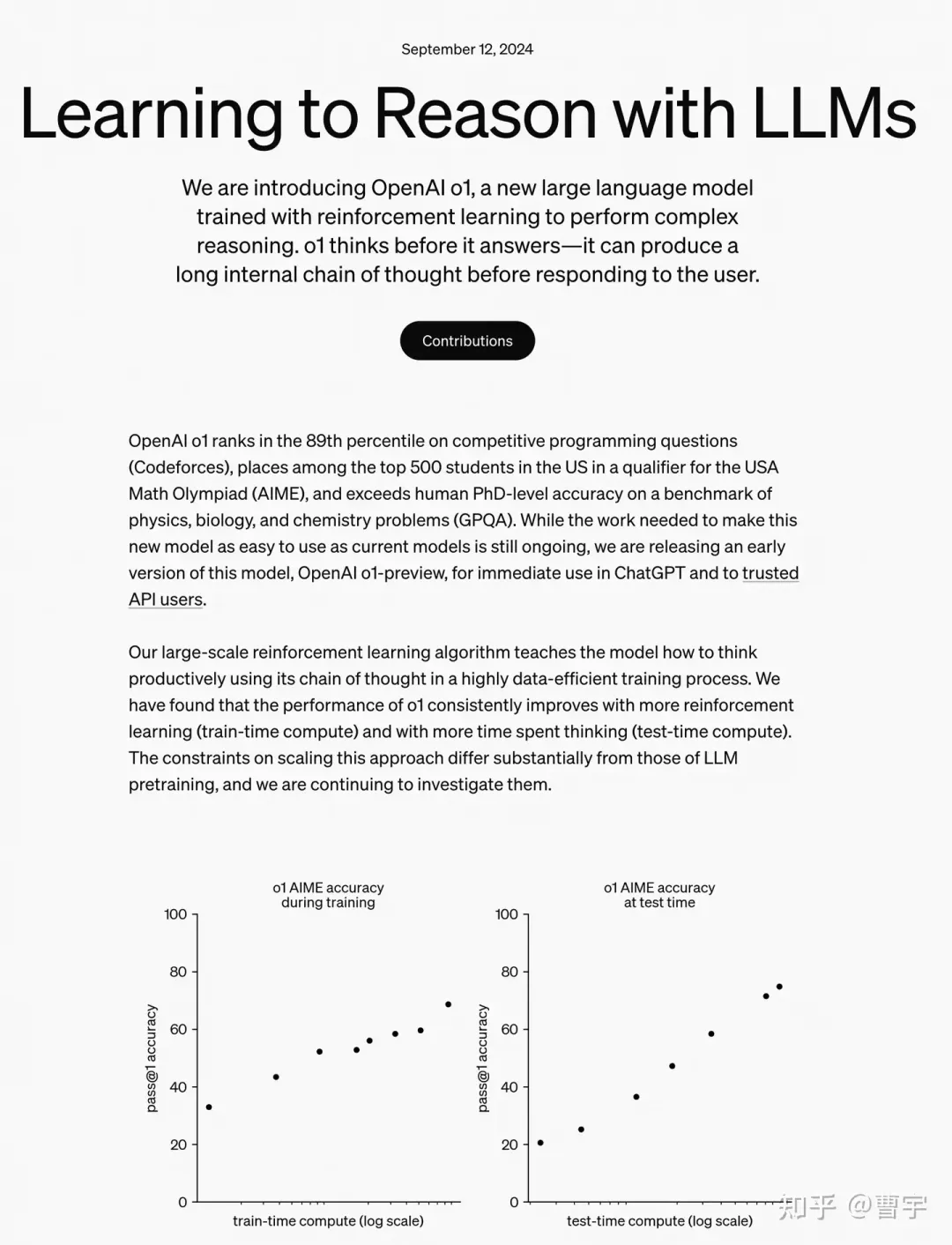
自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。

o1 模型何以成为企业游戏规则的改变者?
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。
Self-play RL 开启 AGI 下半场

本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。

头部模型的新一代模型的是市场观测、理解 LLM 走向的风向标。即将发布的 OpenAI GPT-Next 和 Anthropic Claude 3.5 Opus 无疑是 AGI 下半场最关键的事件。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。