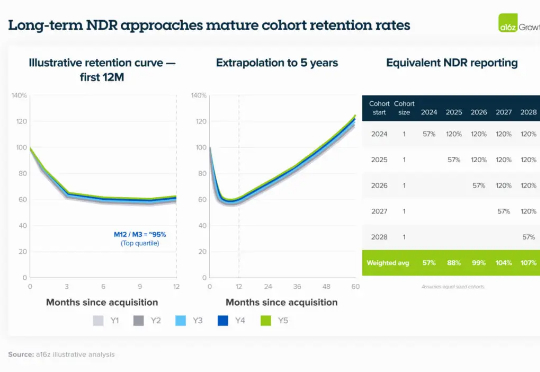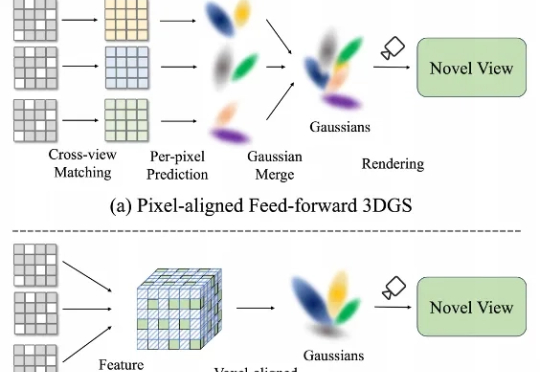
前馈3D高斯泼溅新方法,浙大团队提出“体素对齐”,直接在三维空间融合多视角2D信息
前馈3D高斯泼溅新方法,浙大团队提出“体素对齐”,直接在三维空间融合多视角2D信息在三维重建不断走向工程化的今天,前馈式3D Gaussian Splatting(Feed-Forward 3DGS)正火速走向产业化。 然而,现有的前馈3DGS方法主要采用“像素对齐”(pixel-aligned)策略——即将每个2D像素单独映射到一个或多个3D高斯上。
来自主题: AI技术研报
7046 点击 2025-09-29 14:49