

Qwen开源版Banana来了!原生支持ControlNet
Qwen开源版Banana来了!原生支持ControlNet刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。不仅支持多图融合,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。
来自主题: AI资讯
10040 点击 2025-09-24 09:58
刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。不仅支持多图融合,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。
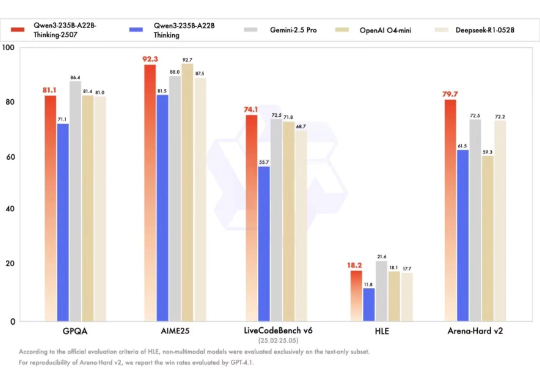
2025 年 9 月 19 日,亚马逊云科技官宣:Qwen3 和 DeepSeek v3.1,首次上线 Amazon Bedrock ,正式对外提供服务,再一次引起了全球生成式 AI 市场对 Amazon Bedrock 这一产品的关注。

CBD 算法则是快手商业化算法团队在本月初公布的新方法,全名 Causal auto-Bidding method based on Diffusion completer-aligner,即基于扩散式补全器-对齐器的因果自动出价方法。
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。

一个从谷歌「打工人」走出的数学怪才,靠着自掏腰包创业,五年把公司做到营收超12亿美元,估值300亿美金。他讨厌硅谷的浮夸,却意外登上《福布斯400》富豪榜,成为最年轻的成员。
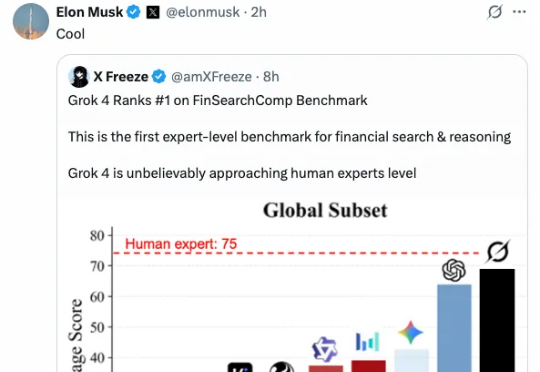
字节跳动Seed团队联合哥伦比亚大学商学院推出了FinSearchComp,这是首个完全开源的金融搜索与推理基准测试。该基准包含635个金融专家精心设计的问题,覆盖全球和大中华两个市场,并在多个主流模型产品上进行了全面评测。

Wayve,一家总部位于英国的无人驾驶初创公司,有望凭一己之力拿到其中的五分之一。该公司日前宣布,已与英伟达签署意向书,后者将在其下一轮融资中“评估 5 亿美元的投资”。同时,Wayve 即将推出的 Gen 3 硬件平台,将完全基于英伟达的 DRIVE AGX Thor 车载计算平台打造。

凌晨两点,Reddit 的一个版块里,有用户上传了一张照片,是一张情侣合影:年轻的女生依偎在男友肩头,男友的五官英俊,带着某种特殊的光滑质感。标题写着:「认识一下,这是我的男朋友。」

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。