
Karpathy刚进Anthropic,转头又投了它
Karpathy刚进Anthropic,转头又投了它AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。
来自主题: AI资讯
8917 点击 2026-06-24 16:59
 搜索
搜索
AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。

据知情人士透露,一家从哈佛大学独立出来的新型人工智能实验室正在与投资者进行谈判,以筹集约1 亿美元,以追求一项听起来像科幻小说的使命 :"一个人类可以记住一切的世界"。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
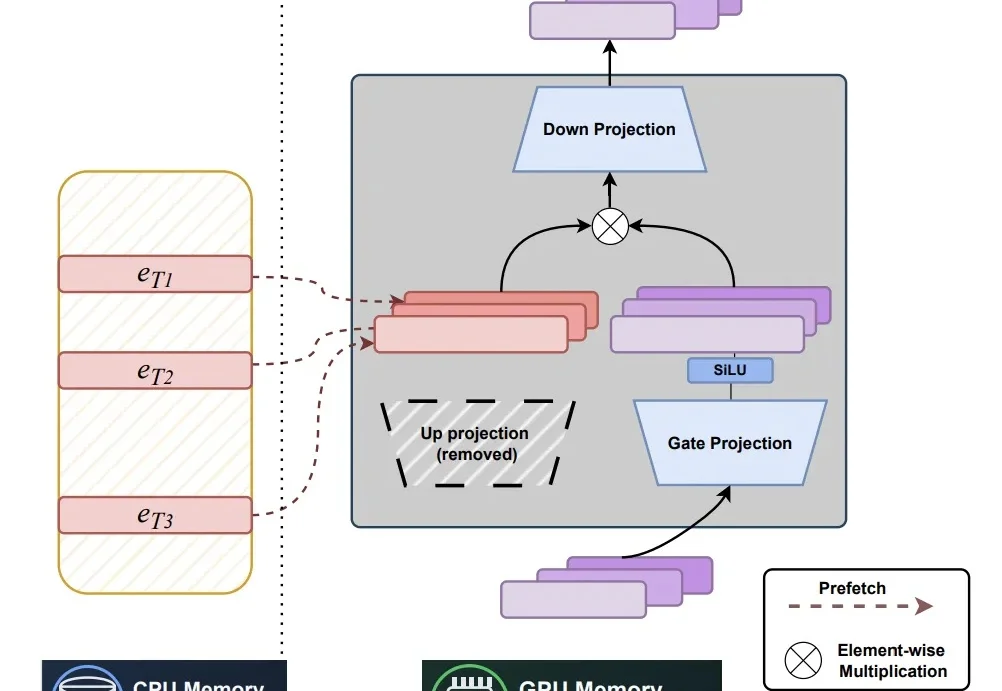
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。

今天DeepSeek又发表了一篇论文,让AI解读,仔细读完,觉得很牛逼。

深夜,梁文锋署名的DeepSeek新论文又来了。这一次,他们提出全新的Engram模块,解决了Transformer的记忆难题,让模型容量不再靠堆参数!

今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。