

英伟达成美国大模型开源标杆:Nemotron 3连训练配方都公开,10万亿token数据全放出
英伟达成美国大模型开源标杆:Nemotron 3连训练配方都公开,10万亿token数据全放出英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:
来自主题: AI资讯
8036 点击 2025-12-26 15:48
英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:

英伟达面向个人的AI超算DGX Spark已上市!128GB统一内存(常规系统内存+GPU显存),加上允许将两台DGX Spark连起来,直接可以跑起来405B的大模型(FP4精度),而这已经逼近目前开源的最大模型!如此恐怖的实力却格外安静优雅,大小与Mac mini相仿,3999美元带回家!
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。

随着大型模型需要处理的序列长度不断增加,注意力运算(Attention)的时间开销逐渐成为主要开销。

首个FP4精度的大模型训练框架来了,来自微软研究院!

老黄在CES上发布的迷你超算Project DIGITS,开启了AI超算的PC时刻。 但随即也引发了不小争议,还遭到了大佬的贴脸嘲讽。

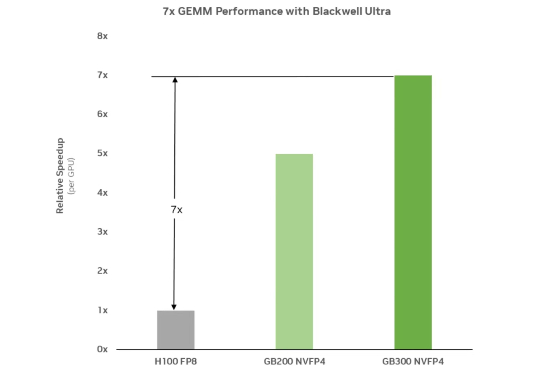
今年GTC大会上,英伟达推出了地表最强Blackwell计算平台、NIM推理微服务、Omniverse Cloud API等惊喜新品。其中Blackwell GPU具有2080亿个晶体管,AI算力直接暴涨30倍。单芯片训练性能(FP8)是Hopper架构的2.5 倍,推理性能(FP4)是Hopper架构的5倍。具有第5代NVLink互连,并且可扩展至576个GPU。