为什么BF16的FlashAttention会把训练「炸掉」?清华首次给出机制解释,用极简改动稳住训练
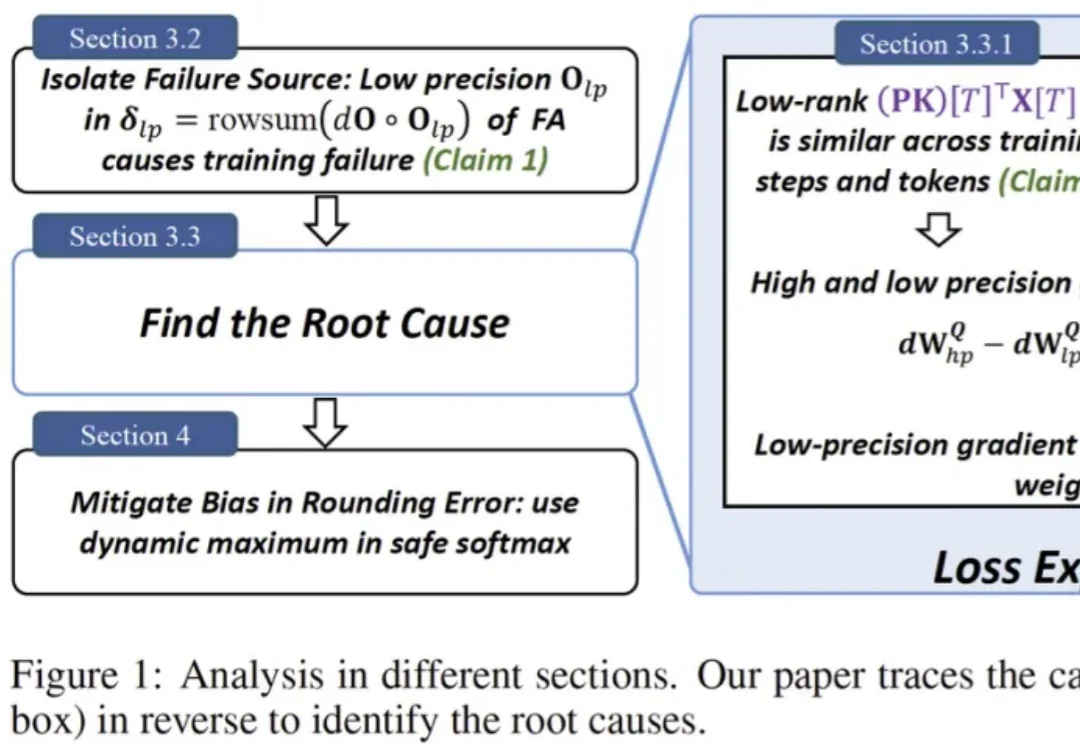
为什么BF16的FlashAttention会把训练「炸掉」?清华首次给出机制解释,用极简改动稳住训练一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
来自主题: AI技术研报
5606 点击 2026-03-04 13:49