
Codex+hyperframe做视频,让剪辑师们慌了?
Codex+hyperframe做视频,让剪辑师们慌了?这两天打开X,发现一个开源项目刷屏了——Hyperframes。GitHub上两天干了17.4k star,1.6k fork,Codex、Cursor、Claude Code的插件全线覆盖。
来自主题: AI技术研报
6568 点击 2026-05-14 10:01
 搜索
搜索
这两天打开X,发现一个开源项目刷屏了——Hyperframes。GitHub上两天干了17.4k star,1.6k fork,Codex、Cursor、Claude Code的插件全线覆盖。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。
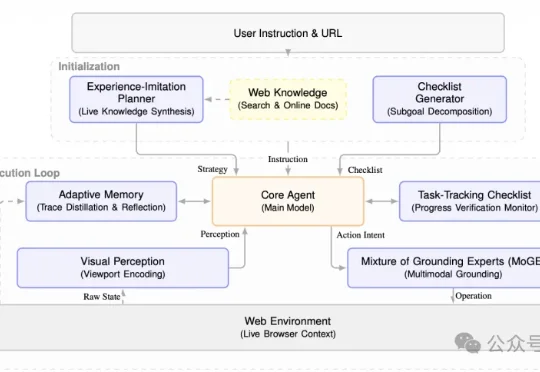
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。

身边做短视频的朋友,几乎人手一个剪映。

AGI,究竟如何评判?刚刚,谷歌DeepMind发出重磅论文,直接从认知科学「借」了一套度量衡——把通用智能拆成10大认知能力,配一套三阶段评估协议,还联合Kaggle砸了20万美金,向全球研究者悬赏:谁能测出真正的AGI?

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),
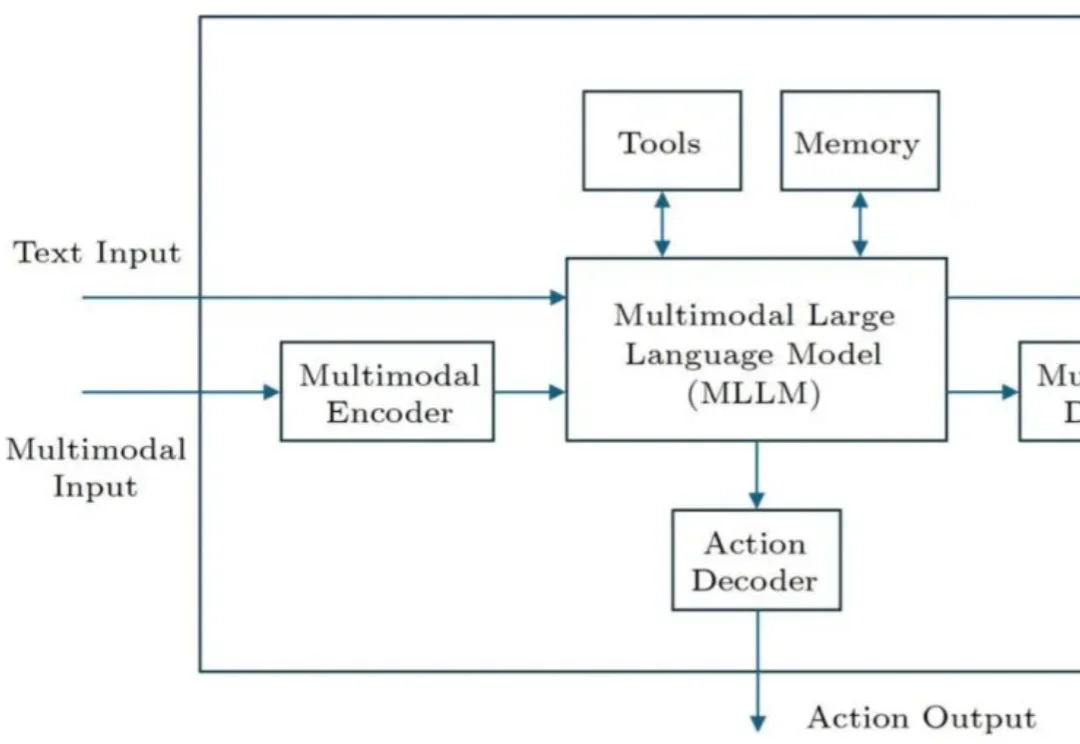
AI 智能体是人工智能领域的重要研究方向之一。近期,字节跳动的李航博士在我国计算机科学领域顶级期刊 Journal of Computer Science and Technology(JCST)上发表了一篇题为《General Framework of AI Agents》的观点论文(将收录于 JCST 创刊 40 周年专辑),提出了一个涵盖软件智能体和硬件智能体的通用框架。
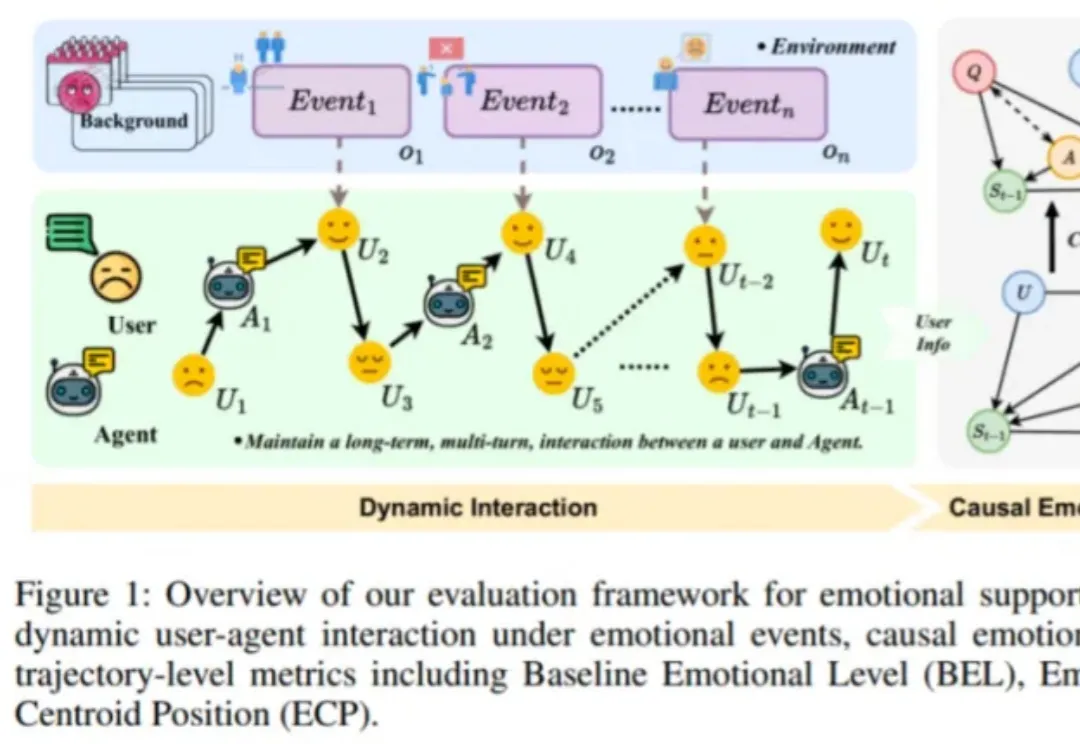
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。
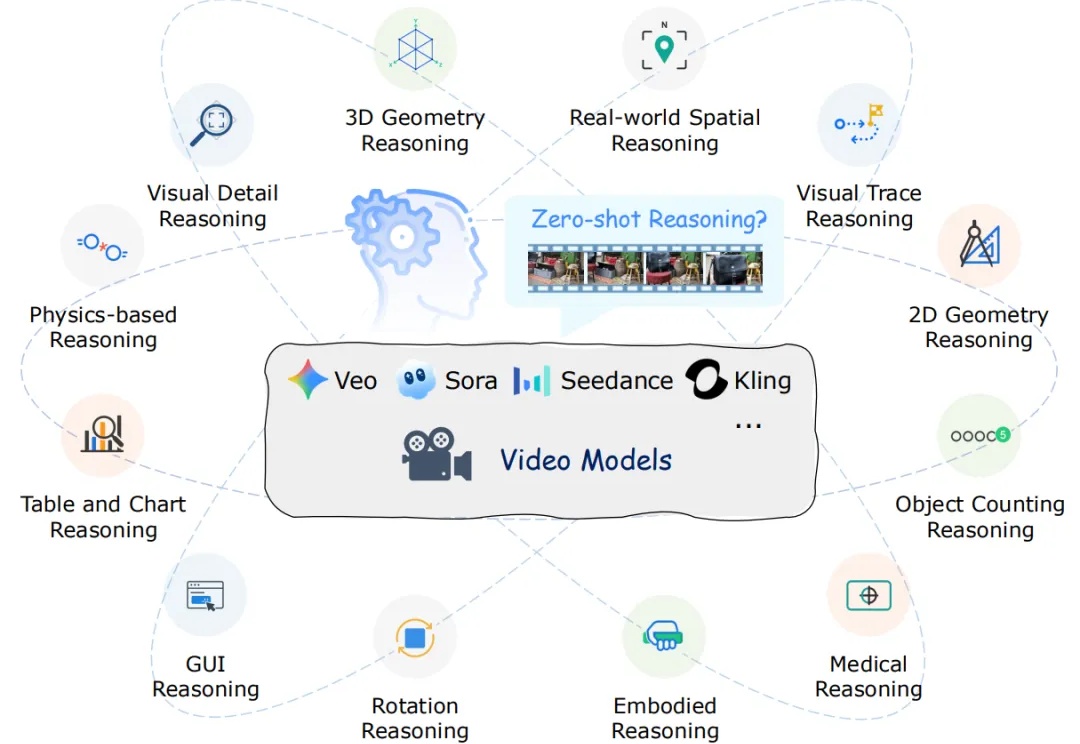
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。