
PPIO这家AI Infra公司为什么做了一个“中国版的E2B”?
PPIO这家AI Infra公司为什么做了一个“中国版的E2B”?中国首个推出兼容E2B接口Agent沙箱的公司。7月26日,2025世界人工智能大会(WAIC)现场人头攒动。在科技要素拉满的会场内,几乎每个展台都在讨论大模型和AI Agent。
来自主题: AI资讯
8219 点击 2025-08-02 13:52
 搜索
搜索
中国首个推出兼容E2B接口Agent沙箱的公司。7月26日,2025世界人工智能大会(WAIC)现场人头攒动。在科技要素拉满的会场内,几乎每个展台都在讨论大模型和AI Agent。

新加坡深度科技初创公司SixSense 开发出一款人工智能平台,可帮助半导体制造商实时预测并检测生产线上潜在的芯片缺陷。该公司已在A 轮融资中筹集 850 万美元,使其总融资额达到约 1200 万美元。本轮融资由 Peak XV 旗下 Surge 基金(原红杉印度及东南亚)领投,Alpha Intelligence Capital、FEBE 等机构跟投。

昨夜,谷歌宣布向 Google AI Ultra 订阅用户推出 Deep Think 功能,Gemini 2.5 Deep Think 模型在今年的国际数学奥林匹克竞赛 (IMO) 上夺得金牌。

谷歌拿下IMO(国际数学奥林匹克竞赛)金牌的模型——Gemini 2.5 Deep Think,现在可以用起来了。谷歌拿下IMO(国际数学奥林匹克竞赛)金牌的模型——Gemini 2.5 Deep Think,现在可以用起来了。
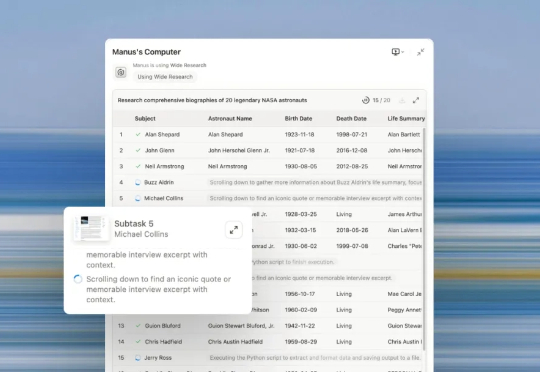
一个 Agent(智能体)不够用?Manus 干脆给你拉来 100 个。 今天凌晨,Manus 推出了一项新功能:Manus Wide Research。这项功能的核心亮点在于,用户只需一键即可开启大规模并行 Agent 协作,轻松处理原本需要耗费数小时、动用数百个数据源的复杂调研任务。

今年WAIC现场,AI硬件公司未来智能现场展出了其今年刚刚推出的两款新品AI会议耳机Pro 3和Air 2,其中内置了面向个人商务办公场景的AI Agent——viaim大脑。

总部位于硅谷致力于构建Agentic OS (AOS)的初创公司Creao AI宣布已连续完成两轮融资。

大模型时代,AI基建的重要性已经不言而喻。
不知道大家有没有遇到过这些“AI 用着用着就想骂人”的时刻? 一个 Agent 从头跑到尾,慢得像蜗牛,一崩还得全盘重来?工具定型、流程固化,每次用都像在迁就它?想让 AI 融入自己的工作流,却发现定制起来堪比造火箭?执行结果不可控,失败了还不会复盘重来,只能你兜底?还有不停上涨的订阅费......
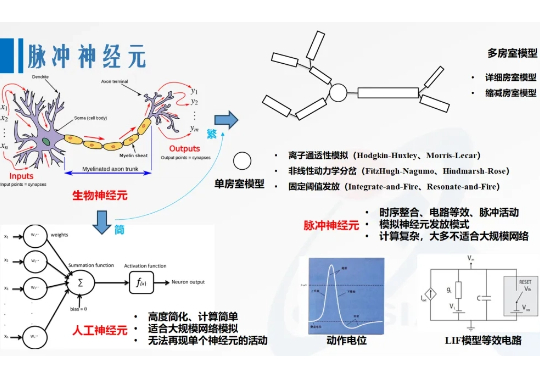
1997年,Wolfgang Maass于Networks of spiking neurons: The third generation of neural network models一文中提出,由脉冲神经元构成的网络——脉冲神经网络(SNN),能够展现出更强大的计算特性,会成为继人工神经网络后的“第三代神经网络模型”[6]。