十亿级参数,千亿级性能,上海AI Lab发布新一代文档解析大模型,复杂场景解析精度媲美人类专家
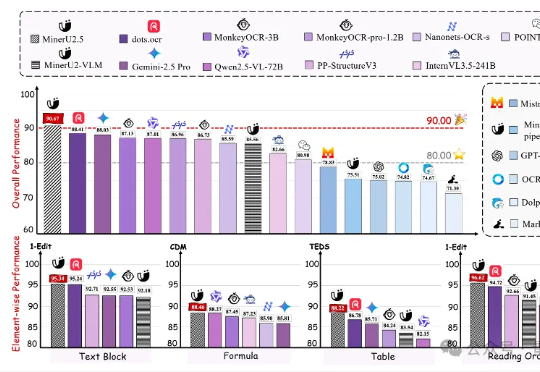
十亿级参数,千亿级性能,上海AI Lab发布新一代文档解析大模型,复杂场景解析精度媲美人类专家上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
来自主题: AI技术研报
10197 点击 2025-09-30 10:45