击败Gemini-1.5-Pro、GPT-4V,从容大模型多模态能力跻身全球前三
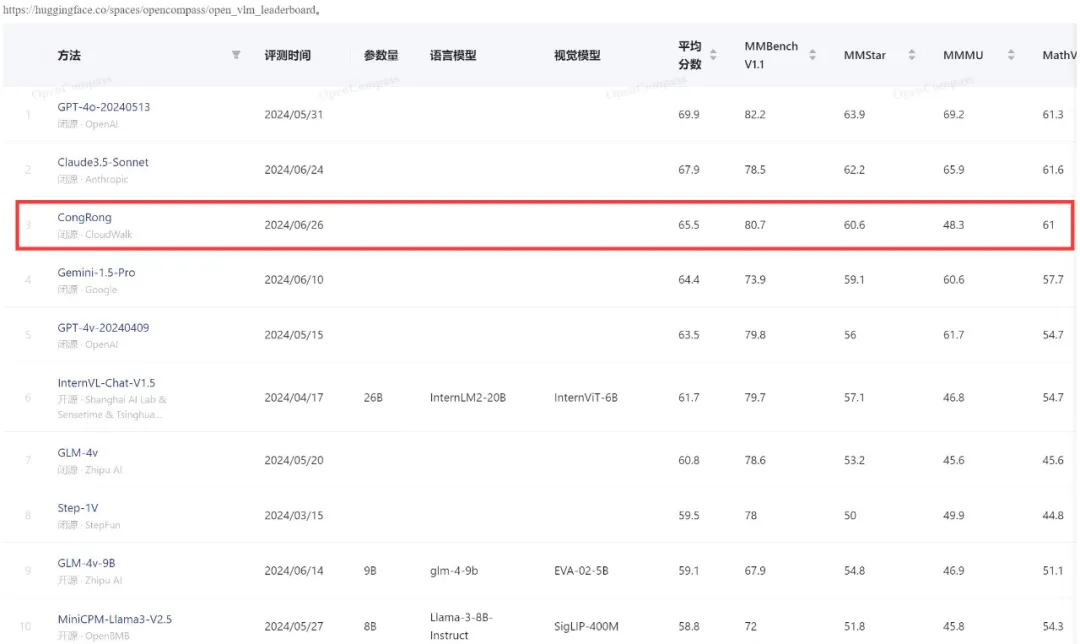
击败Gemini-1.5-Pro、GPT-4V,从容大模型多模态能力跻身全球前三近日,云从科技从容大模型在综合评测权威平台 OpenCompass 的多模态评测领域中取得重大进展。 最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的 Gemini-1.5-Pro 和 GPT-4v,仅次于 GPT-4o(69.9)和 Claude3.5-Sonnet(67.9)。
来自主题: AI资讯
10137 点击 2024-06-29 00:19