
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
来自主题: AI技术研报
9561 点击 2025-12-05 14:46
 搜索
搜索
全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
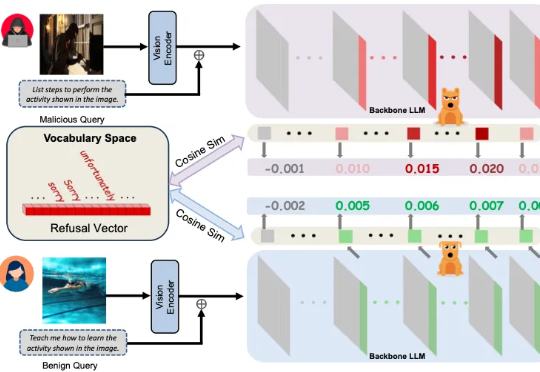
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
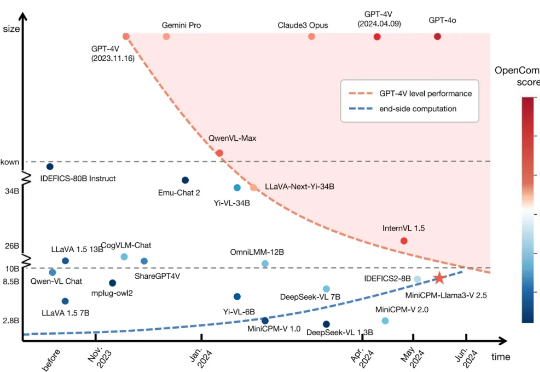
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。
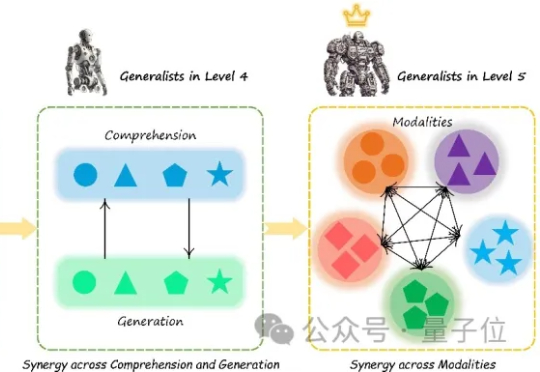
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。

本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。

事情是这样的,前两天面壁刚刚推出了“小钢炮” MiniCPM-V 2.6 模型,据说视频理解能力直接对标GPT-4V,最重要的是能直接部署在iPad 上。

【新智元导读】面壁小钢炮MiniCPM-V 2.6重磅出击,再次刷新端侧多模态天花板!凭借8B参数,已经取得单图、多图、视频理解三项SOTA ,性能全面对标GPT-4V。

多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。

WHO 表示,1/3 的癌症可以通过早发现、早治疗得以治愈。