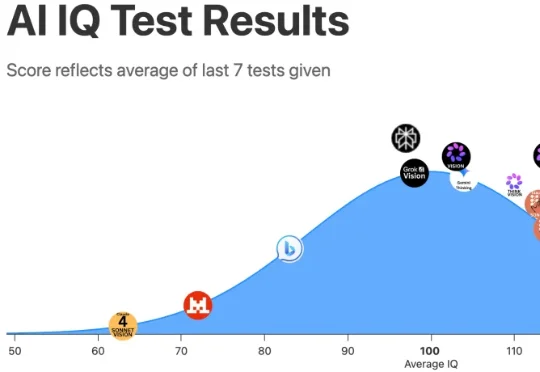
GPT-5.6智商首破130天才线!比99%人类聪明
GPT-5.6智商首破130天才线!比99%人类聪明见证历史!
来自主题: AI资讯
6746 点击 2026-07-16 15:17
 搜索
搜索
见证历史!

GPT-5.6发布之后,Codex开始以一种近乎夸张的速度增长。

困扰统计学界整整20年的核心悬案,被AI击碎了。

又送了! 就在刚刚,Codex与ChatGPT Work的活跃用户大军,合体突破800万大关。
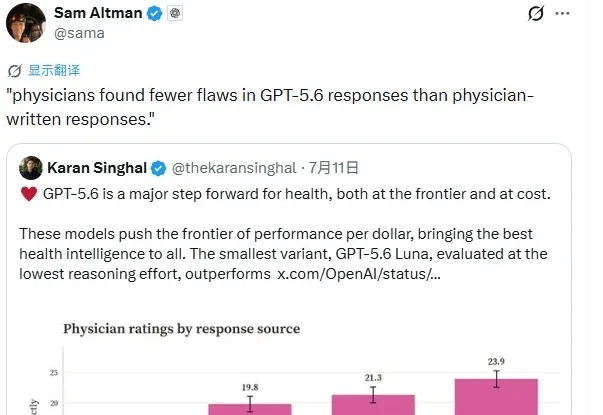
近期,OpenAI推出其GPT-5.6系列模型,号称是地表最强模型。
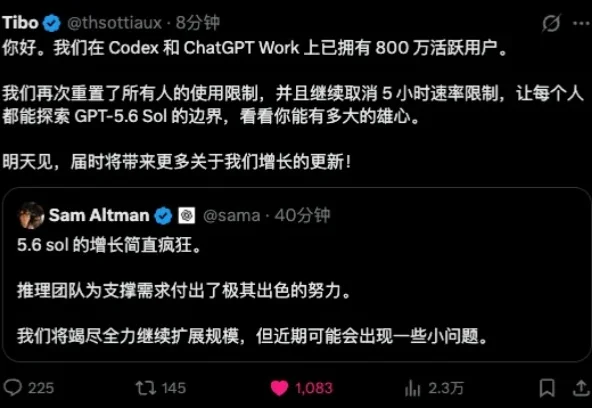
最近两周,因为Claude Fable 5回归、GPT-5.6上线再加上Tibo义父疯狂的重置。

还得是厂商内卷,造福用户啊……AI圈也迎来了自己的百亿补贴。

人眼秒懂、顶级AI全瞎的「幽灵字体」一夜爆火1700万播放,结果一句提示词就让GPT-5.6破防了。

OpenAI高管亲自下场,教开发者5分钟极速「策反」Claude Code,这波贴脸开大太狠了。

这一天天的,OpenAI的安全负责人怎么接二连三地跑路啊…