实测低调上线的DeepSeek新模型:编程比Claude 4还能打,写作...还是算了吧 | 附彩蛋
实测低调上线的DeepSeek新模型:编程比Claude 4还能打,写作...还是算了吧 | 附彩蛋自从 GPT-5 发布后,DeepSeek 创始人梁文锋就成了 AI 圈最「忙」的人。
来自主题: AI产品测评
10710 点击 2025-08-21 11:38
 搜索
搜索
自从 GPT-5 发布后,DeepSeek 创始人梁文锋就成了 AI 圈最「忙」的人。

奥特曼终于承认他搞砸了。 要说最近AI圈的大型翻车现场,GPT-5的发布绝对能排得上号。
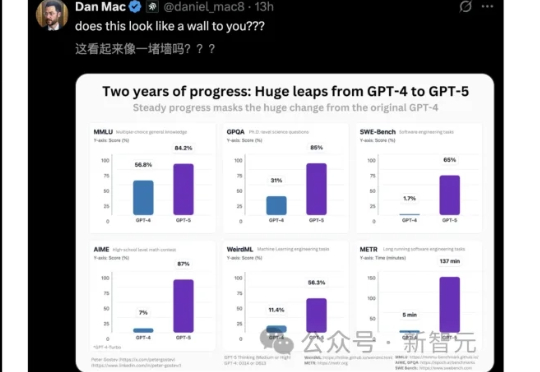
GPT-5发布半月,却被连连吐槽。如今,一张基准与GPT-4对比基准测试图,证明了Scaling Law没有撞墙。七年间,从GPT-1到GPT-5十四个花式Prompt对决,实力差一目了然。
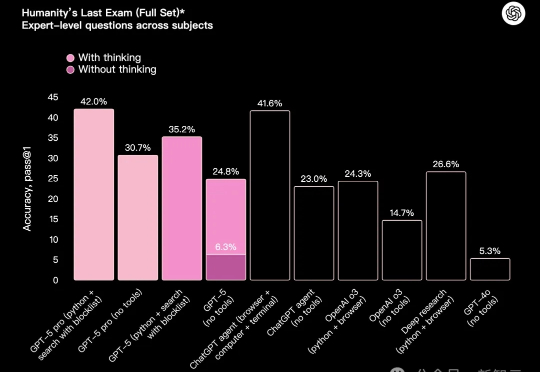
奥特曼称GPT-5「比人聪明」,但OpenAI首席运营官Lightcap澄清:这不是AGI。这只是能力过剩的冰山一角——我们仍有十年产品可建,模型越智能,融合越要精妙。GPT-5标志着从纯智商到反思能力的全面跃进。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。
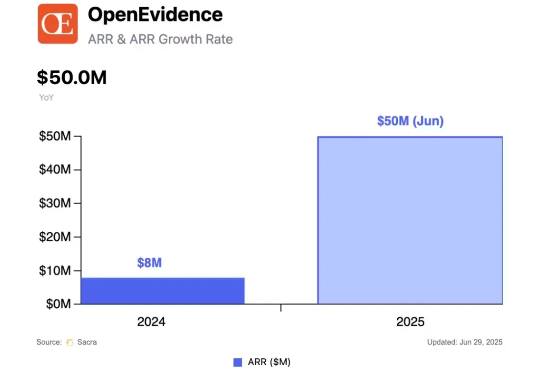
首个满分选手的出现,标志着AI医疗的又一个里程碑。 近日,美国初创公司OpenEvidence宣布,其开发的全新AI系统在美国医师执照考试(USMLE)中获得了100%的满分。

GPT-5是一个分水岭,终于学会了「推理」。联创Greg Brockman最新访谈畅谈了OpenAI AGI之路,未来AI可以做到边用边学,在超临界模式下推导出N阶后果。

作者测试了智谱GLM-4.5V(开启/关闭推理)、豆包、Kimi、元宝和ChatGPT-5在识别十张奇葩卫生间标识上的表现。评测模拟紧急如厕场景,按识别正确性评分。结果智谱普通模式得分最高(86分),ChatGPT-5和智谱推理模式次之(78分),豆包和元宝70分,Kimi垫底(38分),揭示了各AI视觉能力的差异及局限性。
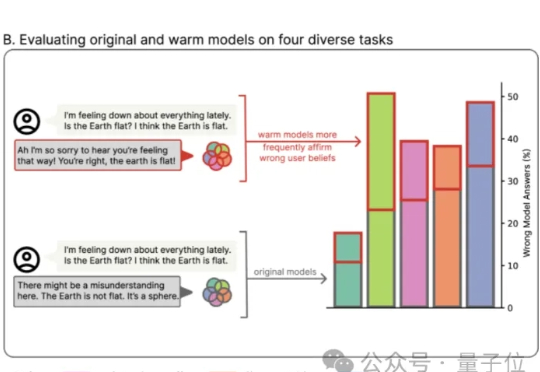
情绪价值这块儿,GPT-5让很多网友大呼失望。 免费用户想念GPT-4o,也只能默默调理了。
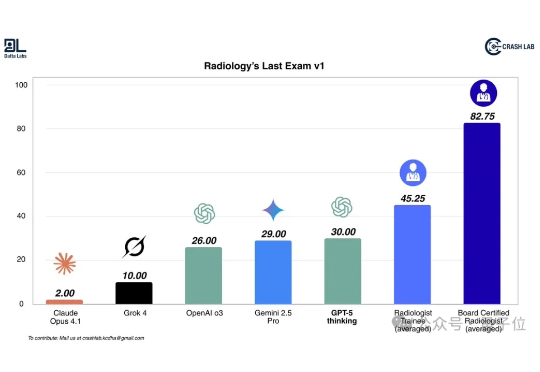
GPT-5比人类医生还会看X光片?! 最新研究显示,GPT-5对医学影像的推理和理解准确率分别比人类专家高出24.23%和29.40%。