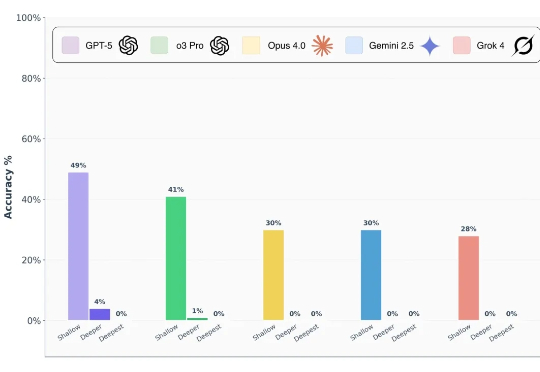
GPT-5、Grok 4、o3 Pro都零分,史上最难AI评测基准换它了
GPT-5、Grok 4、o3 Pro都零分,史上最难AI评测基准换它了前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?
来自主题: AI资讯
9891 点击 2025-08-15 20:41
 搜索
搜索
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?

GPT-5发布以来,路由架构是最受关心的部分之一。它不仅实现了多个模型统一调度,而且还藏着奥特曼的诸多小心思。比如成本更可控、悄悄识别意图插入广告等。

GPT-5一上线,用户瞬间破防——太冷漠,太爹味,还我GPT-4o!就在刚刚,奥特曼彻底滑跪了,宣布GPT-4o满血复活,重回默认模型宝座。从曾经的遭人唾弃,到今日的白月光回归,ChatGPT的用户们给奥特曼结结实实上了一课。
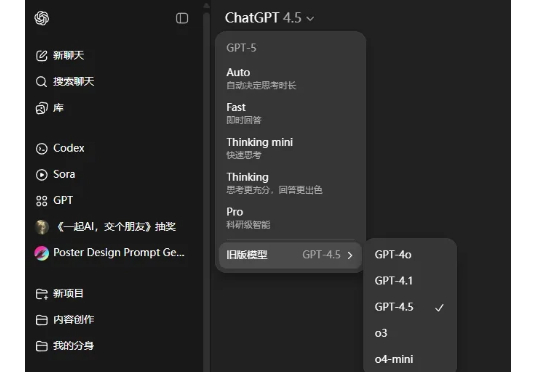
GPT-5和“还我GPT-4o”的风波,闹得沸沸扬扬。 今天,奥特曼还有一次认怂了,不仅调了UI,还把o3这些老模型还了回来。

GPT-5刚发布没多久,DeepSeek-R2就快来了,好热闹的8月份! DeepSeek预计将于8月发布其新一代旗舰模型DeepSeek-R2。
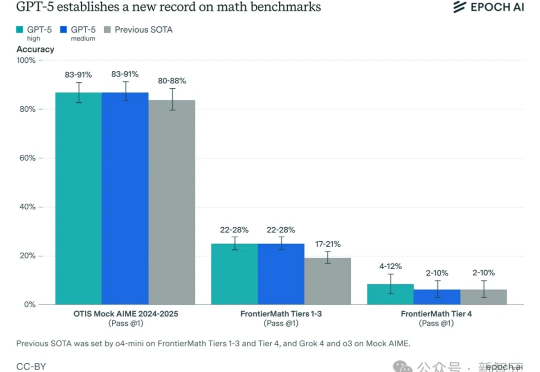
GPT-5来了!智商148、数学纪录被刷新、英伟达点头认可,但OpenAI真正的杀手锏,不在智商,而在分配智商的「路由器」。

最近 AI 界的大新闻是 GPT-5 和谷歌的世界模型 Genie 3。然而,在无人在意的角落里,微软悄悄把 Edge 进化成了了 AI 浏览器。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。

危险!ChatGPT存在“零点击攻击”安全问题。 用户无需点击,攻击者也能从ChatGPT连接的第三方应用窃取敏感数据,甚至窃取API密钥。

GPT-5是一次 ChatGPT 产品的重要升级。Routing 能力的加入帮助 ChatGPT 模型第一次把产品线捋顺统一,是 UX 交互的一次重要革新。就像 Apple 决定只推出一款 iPhone 产品线,短期用户可能被迫适应 GPT-5 这个旗舰产品的优缺点,但长期更容易占领用户心智。