
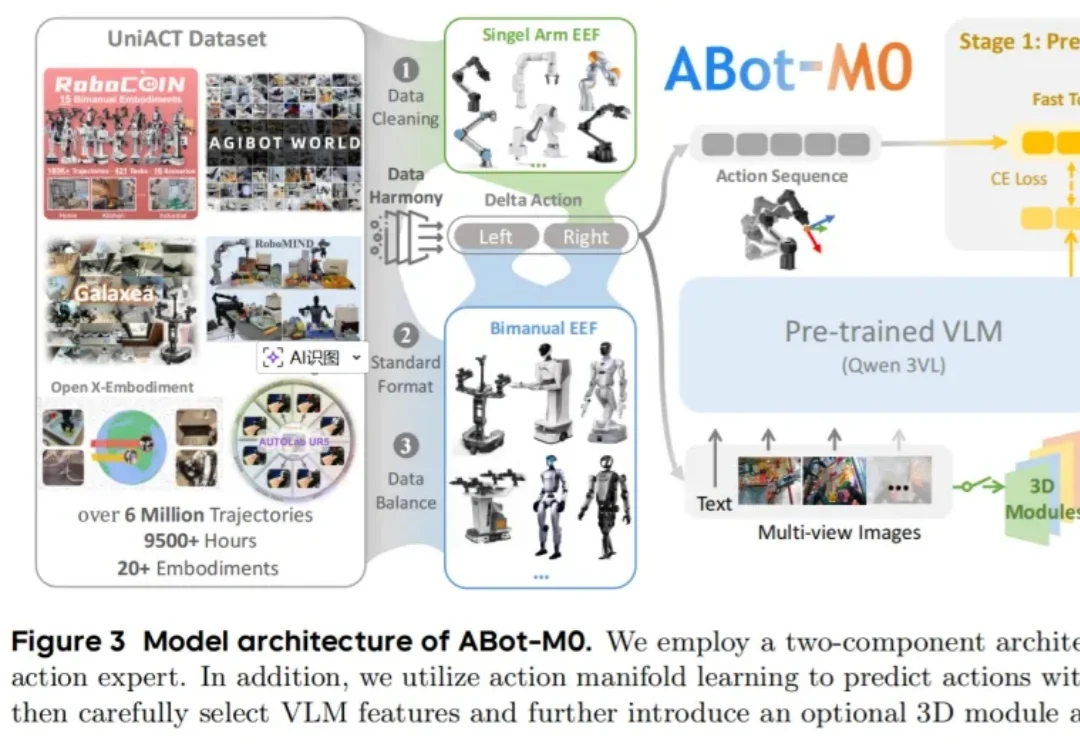
具身智能的「GPT时刻」?高德连发两个全面SOTA的ABot具身基座模型
具身智能的「GPT时刻」?高德连发两个全面SOTA的ABot具身基座模型过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。
来自主题: AI技术研报
6316 点击 2026-02-13 12:02
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。
春节还没到,「过年的气氛」已经渗入科技圈每个人的毛孔。单说 AI 大模型这一块,刚刚发布的有 kimi 2.5 和 Step 3.5 Flash,即将发布的据说还有 DeepSeek V4,GPT-5.3、Claude Sonnet 5、Qwen 3.5,GLM-5,说不定一觉醒来,现有的技术就要被颠覆。
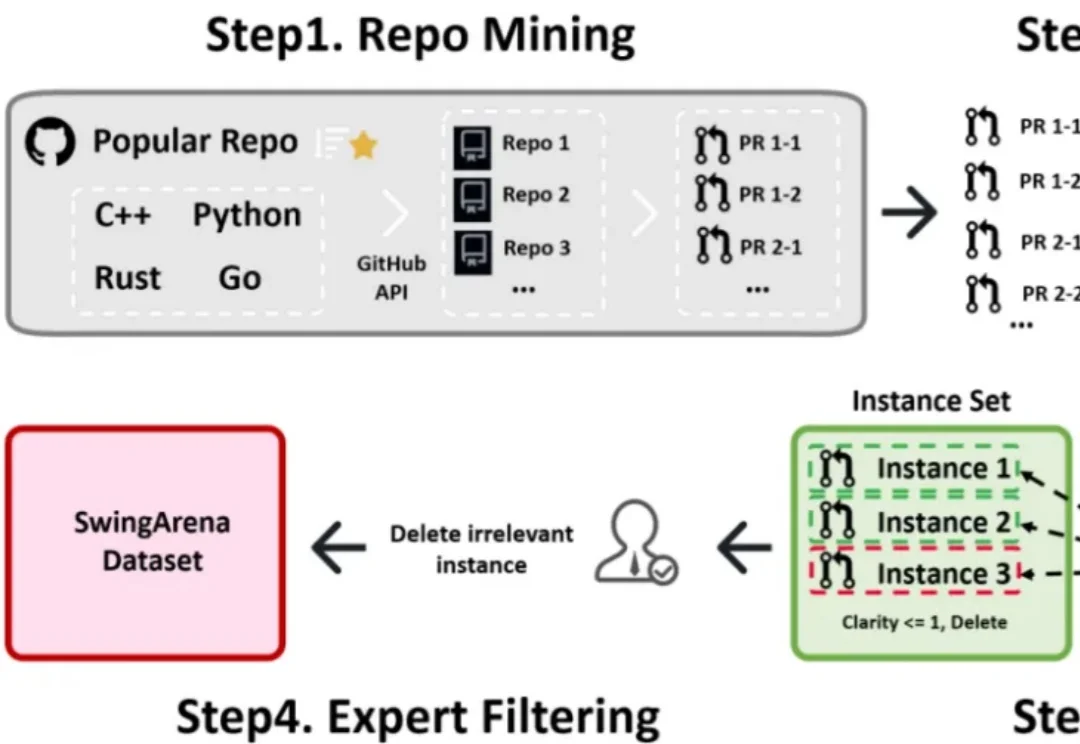
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。

就在这个被 Anthropic 和 OpenAI 视为衡量 Agent 真实工程能力全球权威基准 Terminal-Bench 2.0 榜单上,中国团队 Feeling AI 凭借 CodeBrain-1,搭载最新 GPT-5.3-Codex 底座模型,一举冲到 72.9%(70.3%) 并跻身全球排行榜第二,成为榜单前 10 中唯一的中国团队。
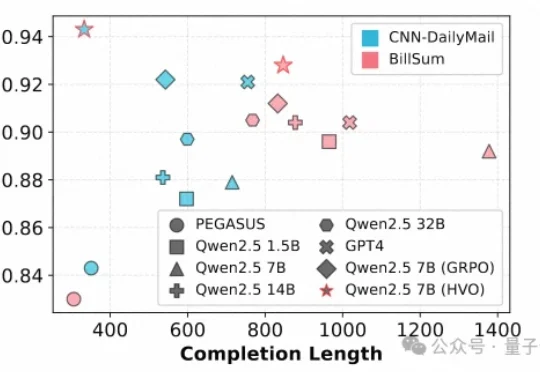
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
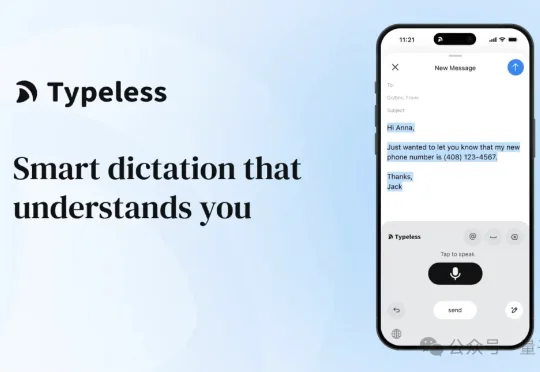
200多块钱每个月,订阅价格直接压过ChatGPT Plus,功能却单一到离谱:只做语音输入一件事。听起来特别像智商税是吧!!!您猜怎么着,据说真就有10万+用户排着队把钱给它送上门。

驱动具身智能进入通用领域最大的问题在哪里?
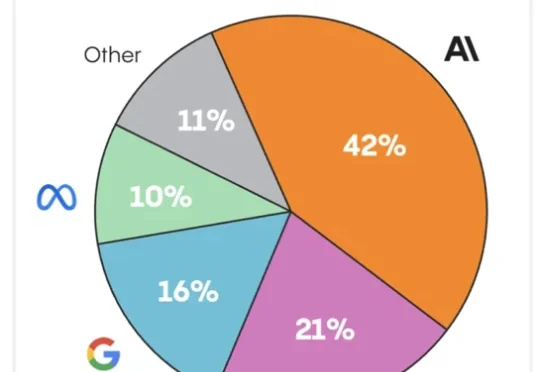
直到OpenAI发布GPT3.5的第3年后,人们才好像恍然意识到:AGI 的 A 其实有可能是Anthropic。
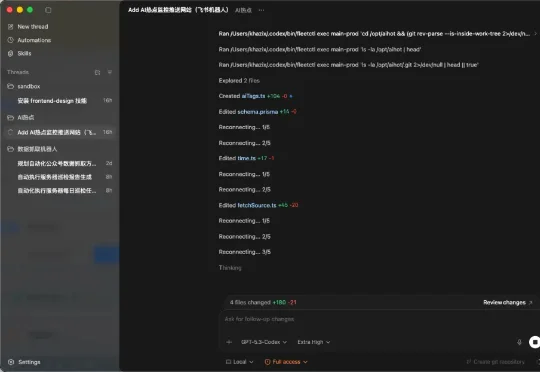
在今天,我可以拍着胸脯说,OpenAI的Codex+GPT-5.3-codex,就是你最佳的入门、进阶、毕业的一条龙产品。你要相信我,愚钝如我,也能在它上面感受到进入心流的爽感,一个周末用它,解决了我四五个过去我完全一个人无法实现的开发需求。
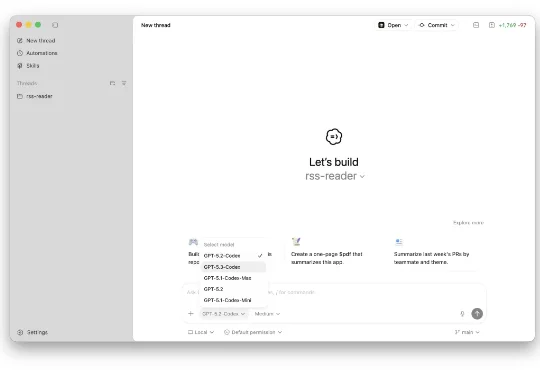
网上对 Codex 的评价在这几天也有了不少逆转,许多开发者从 Claude Code 转向 Codex,一些在国内的独立开发者也表示 Codex Plus 会员就可以用,而且还不会像 Claude 那般总是无情封号。