# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一般人和 ChatGPT 聊天时,往往不会在意要不要讲究礼貌。但来自爱荷华大学的一项最新研究显示:即便回答内容几乎相同,对 ChatGPT 粗鲁无礼也会让你花费更高的输出成本。
这项研究指出,GPT-4 的输出 token 价格大约是每百万输出 token 12 美元。研究者发现:
换句话说,你对 ChatGPT 粗鲁,它会“加班”生成更多无关词语,为自己赚取额外收入。

实际上,在今年早些时候,大家还普遍认为与LLM交流时不需要礼貌。山姆·奥特曼也曾公开抱怨,礼貌用语(如“please”)可能让OpenAI 在计算成本上损失“数千万美元”。

同期还有研究指出,礼貌并不会带来更好的回答,但并未提及是否会带来更便宜的回答。
如果这篇新论文的结论成立,那么那些认为“能少说就少说礼貌用语”的企业用户,在2025 年实际上反而为ChatGPT 支付了更多推理成本。
此外,作者还强调这种反常行为可能揭示出人类与 AI 交互方式中一些尚未理解的机制,而这些机制可能带来潜在的经济影响。至于为什么“不礼貌”会让输出token 增加,论文并未给出推测。
研究者采用了一个很巧妙的实验方法:
他们从WildChat 数据集中抽取 2 万条 GPT-4 提示语,这个数据集包含 100 万条用户与 ChatGPT 的对话,超过 250 万个交互轮次。
接着,他们将这些提示语分成了“礼貌”或“不礼貌”两大类。被标记为“礼貌”的提示语可能包含明显的礼貌词,如 “please”,也可能以更委婉的方式表达礼貌。任何未被模型识别为礼貌的提示语均归类为“不礼貌”,即便它们只是语气中性而非攻击性。
研究者将每条提示语重新改写为语气相反的版本,但尽量保持其他内容不变,然后用 GPT-4-Turbo 测试两者的输出长度。

结果显示:礼貌提示语平均输出少 14.426 个 token,且输出质量与非礼貌提示几乎一致。
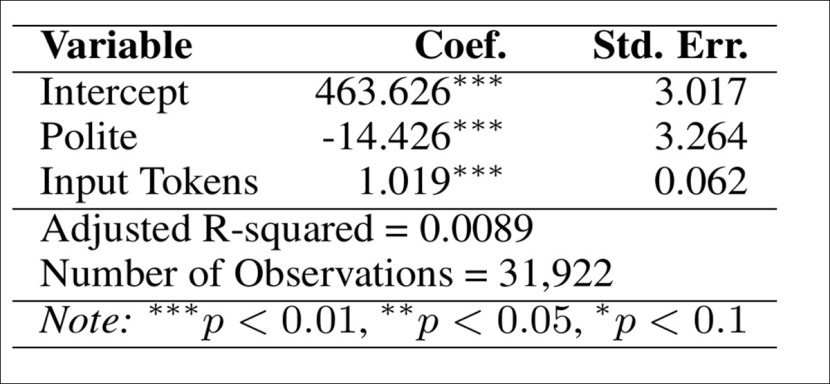
为了进一步了解 token 减少的原因,研究者做了以下两项分析:
1、停用词分析:最常被删掉的词是英语中常见的停用词(like、have、where 等),这些词主要起语法连接或修饰作用,并不影响句子主要意思。
2、短语分析:去掉停用词后,他们还分析了 1 到 4 个词的短语,看是否有某些短语被系统性删掉或保留。结果发现没有特定的、有实际语义的短语被规律性地删掉。
结论:礼貌提示语生成更短输出,并不是因为模型随意删除了有意义的内容或关键短语,而是输出被自然压缩了,语义信息基本保持完整。也就是说,礼貌提示确实让输出更精简,而非礼貌提示会让模型“多说废话”。
为了确保这个结论不是偶然,研究者做了多轮稳健性测试。首先,他们把礼貌提示语分成三类来单独测试:
结果显示,不管哪一类礼貌提示,输出 token 都比不礼貌提示少。
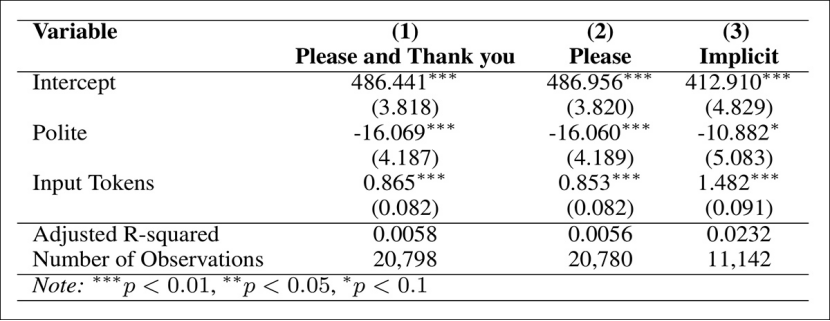
接着,他们引入了 LIWC 框架 做第二轮分类验证。LIWC 可以对每条提示语给出稳定的礼貌评分,不像 GPT 的分类有随机性。规则很简单:
比较发现,LIWC 与 GPT 的分类一致率高达 81%,说明两套系统的判断大体一致。只分析标签一致的提示语,礼貌提示依然平均减少 14 个输出 token;如果把礼貌程度当作连续量表,礼貌度每提升一个等级,平均还能减少约 5 个 token。
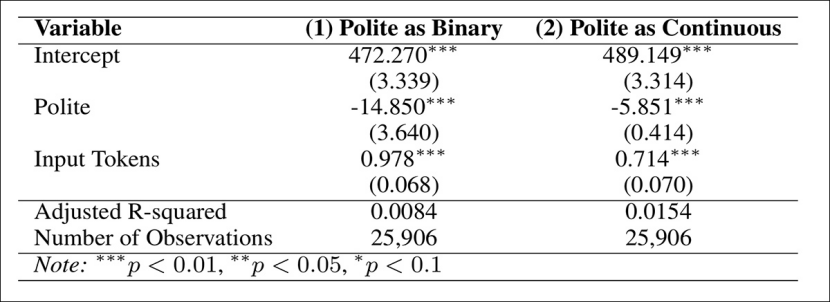
此外,为了测试结论是否会因为任务类型不同而改变,研究者把提示语分到六类任务:信息检索、文本生成、编辑改写、分类、摘要以及技术任务,然后用语义向量(embedding)计算每条提示与各任务的相似度,选择最匹配的任务标签。
控制了任务类型之后,结果显示:在所有情况下,礼貌提示始终生成更短的回答,不同任务类型之间没有显著差异。

有人可能会问:礼貌提示虽然生成的回答更短,但会不会内容缩水、质量下降?研究者专门验证了这个问题。
他们把每条原始提示语和改写后的礼貌/不礼貌版本生成的回答拿来做语义相似性对比。用的是 all-MiniLM-L6-v2 模型,把回答嵌入语义向量空间,然后计算余弦相似度。
结果显示,平均相似度高达 0.78,这说明即便语气发生变化,内容仍保持一致。
研究者还进行了人工评估,由401 名参与者评估 20 对礼貌 / 不礼貌提示语输出,同样发现,两者的输出内容并无显著质量差异。
对于企业而言,研究者指出,直接限制 token 数量并不可靠:
目前更可靠的做法是:写 prompt 时保持礼貌,既能保持回答质量,也能节约企业成本。
尽管该研究主要关注企业用户的 ChatGPT 使用情况,但普通用户也会受到这种现象影响,因为即便是入门级账户也有使用限制。如果粗鲁对待ChatGPT ,会更快消耗掉每日token 配额。
此外,研究者还呼吁:企业用户、LLM 服务提供商以及政策制定者,都应关注 输出 token 成本透明化,因为语言的微小变化可能会带来大额开销。
在最后,研究者也强调,礼貌现象可能只是更深层次语言奇异性的一种指示,而这些尚未被发现的语言特性,很可能正影响着推理成本。
所以,下次写 ChatGPT 提示语时,多加一个“请”,不仅礼貌,还能省钱!
参考链接:
https://arxiv.org/pdf/2511.11761
文章来自于“51CTO技术栈”,作者 “听雨”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
