陈天奇新书上线:面向ML系统的现代GPU编程
陈天奇新书上线:面向ML系统的现代GPU编程前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
来自主题: AI资讯
8223 点击 2026-06-27 15:49
 搜索
搜索
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
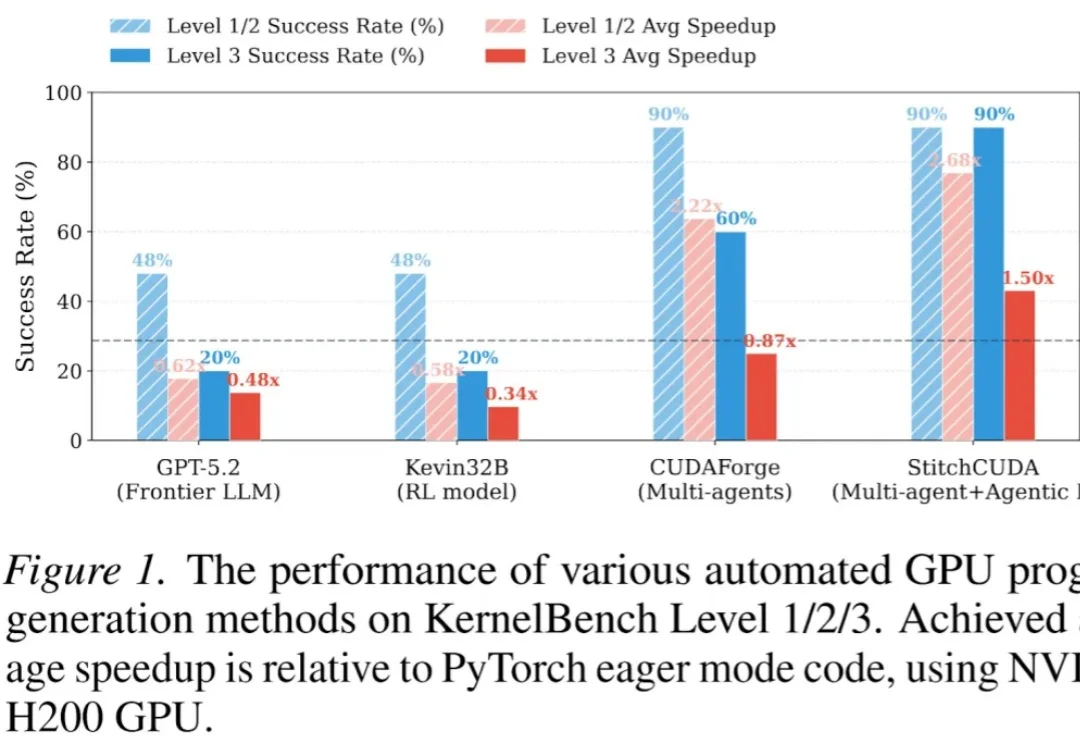
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。
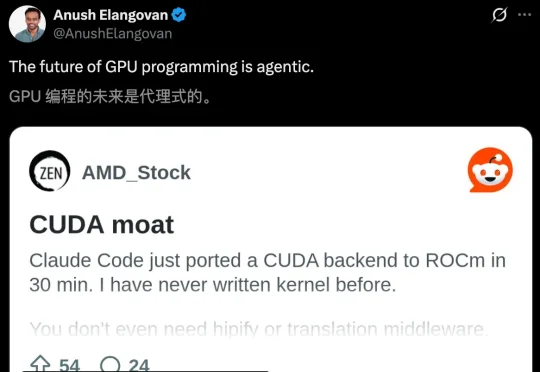
英伟达护城河要守不住了?Claude Code半小时编程,直接把CUDA后端迁移到AMD ROCm上了。 一夜之间,CUDA护城河被AI终结了? 这几天,一位开发者johnnytshi在Reddit上分享了一个令人震惊的操作:

GPU编程变天了。

CUDA 迎来 “Python元年”!

斯坦福和普林斯顿研究者发现,DeepSeek-R1生成的自定义CUDA内核,完爆了o1和Claude 3.5 Sonnet,拿下总排名第一。虽然目前只能在不到20%任务上超越PyTorch Eager基线,但GPU编程加速自动化的按钮,已经被按下!

近日,来自 CMU 的 Catalyst Group 团队发布了一款 PyTorch 算子编译器 Mirage,用户无需编写任何 CUDA 和 Triton 代码就可以自动生成 GPU 内核,并取得更佳的性能。