
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
来自主题: AI技术研报
9385 点击 2025-11-28 09:28
 搜索
搜索
基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
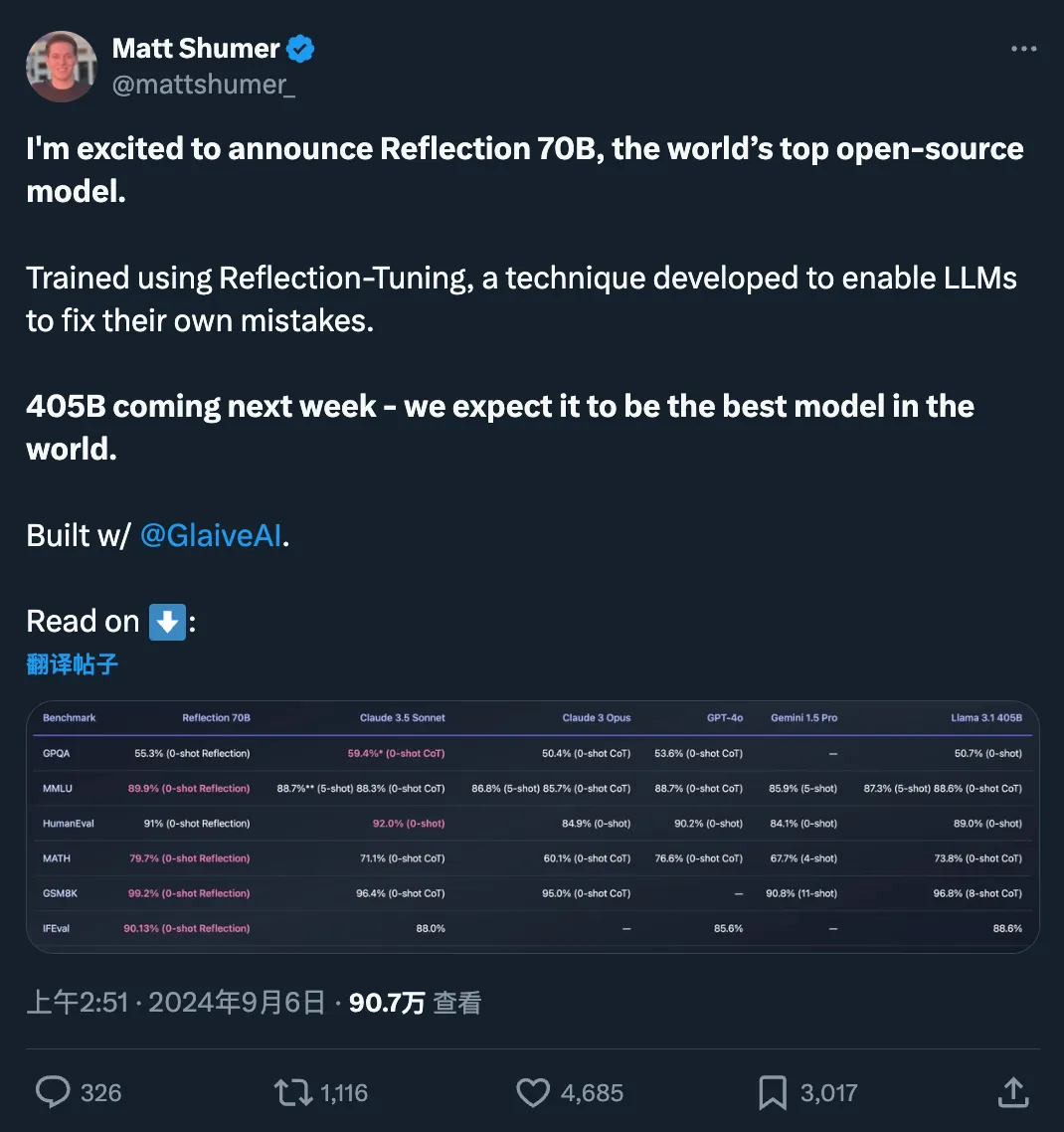
快速更迭的开源大模型领域,又出现了新王:Reflection 70B。 横扫 MMLU、MATH、IFEval、GSM8K,在每项基准测试上都超过了 GPT-4o,还击败了 405B 的 Llama 3.1。 这个新模型 Reflection 70B,来自 AI 写作初创公司 HyperWrite。

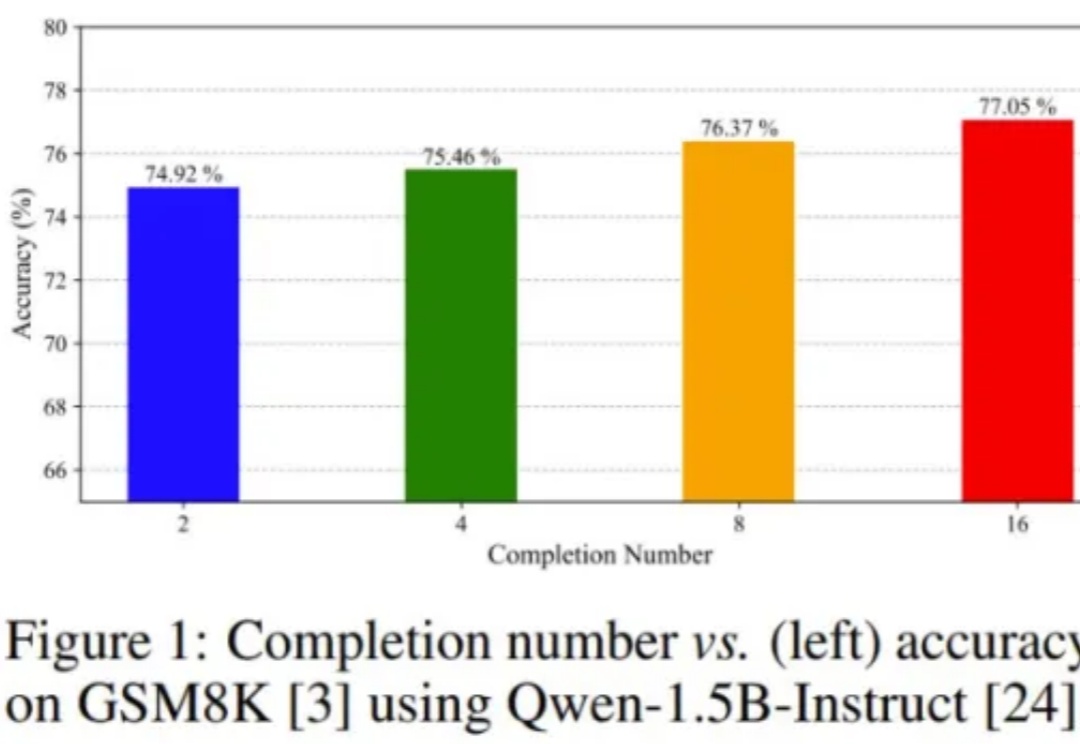
只要不到10行代码,就能让大模型数学能力(GSM8k)提升20%!
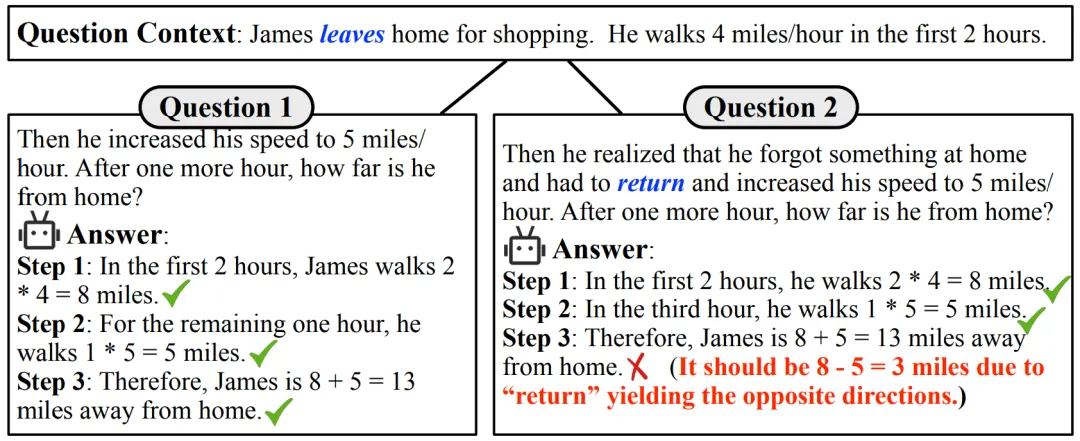
大型语言模型(LLMs)在解决问题方面的非凡能力日益显现。最近,一个值得关注的现象是,这些模型在多项数学推理的基准测试中获得了惊人的成绩。以 GPT-4 为例,在高难度小学应用题测试集 GSM8K [1] 中表现优异,准确率高达 90% 以上。同时,许多开源模型也展现出了不俗的实力,准确率超过 80%。
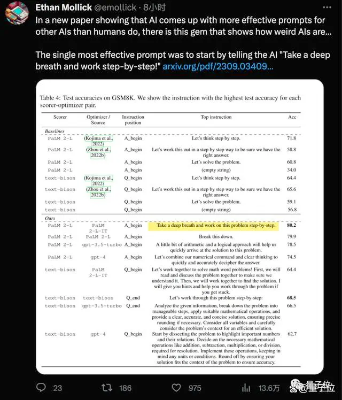
谷歌DeepMind团队最新发现,用这个新“咒语”(Take a deep breath)结合大家已经熟悉的“一步一步地想”(Let’s think step by step),大模型在GSM8K数据集上的成绩就从71.8提高到80.2分。