
谷歌全家桶,都被新模型“污染”了
谷歌全家桶,都被新模型“污染”了距离谷歌的Gemini 3.5 Flash发布已经一周多了。
来自主题: AI资讯
6141 点击 2026-05-28 09:51
 搜索
搜索
距离谷歌的Gemini 3.5 Flash发布已经一周多了。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

天下武功,唯快不破。
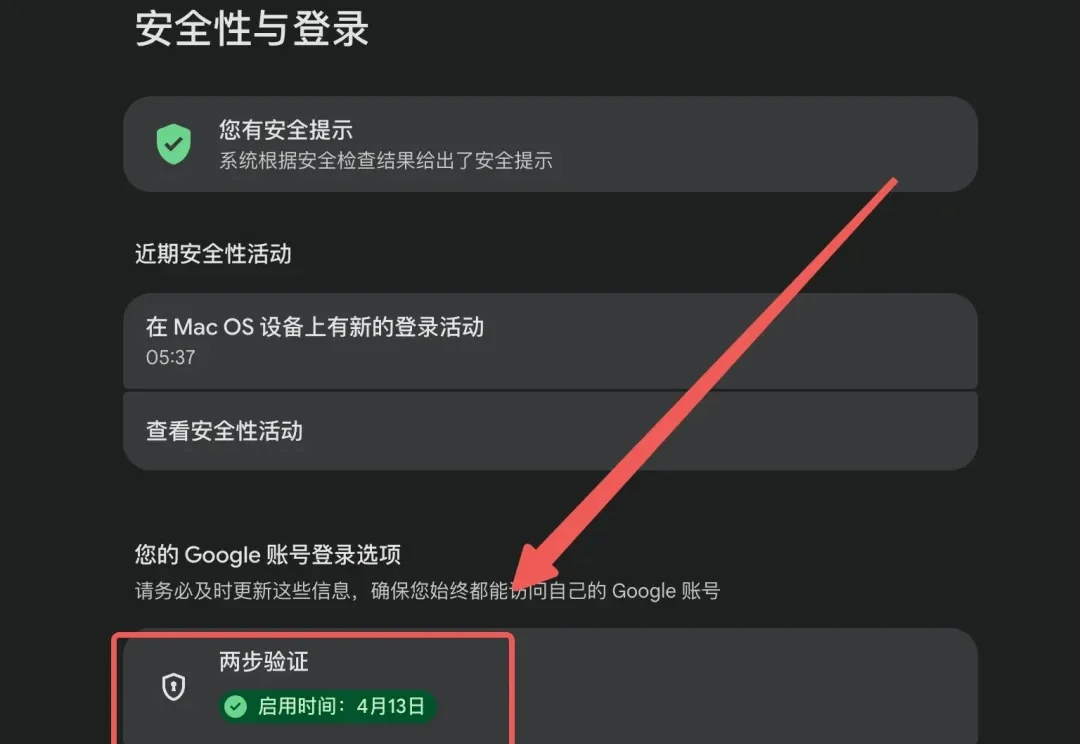
去年带大家靠学生优惠白嫖了一年的 Gemini Pro,前几天发邮件提醒我快到期了。

谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了: 在Coding这事儿上,我们家Gemini确实有点了落后哈…..

近日,谷歌在2026 I/O大会上发布了旗下AI for Science工具组合Gemini for Science。 该组合包含了谷歌旗下三款顶尖的AI科研工具,能实现假设生成、计算发现和文献综述的

Google把科学研究的三个核心瓶颈:假设生成、计算发现、文献洞察拆解为三个可由AI深度辅助的模块,并同日发表两篇Nature论文,为假设生成和计算发现两大环节提供支撑。
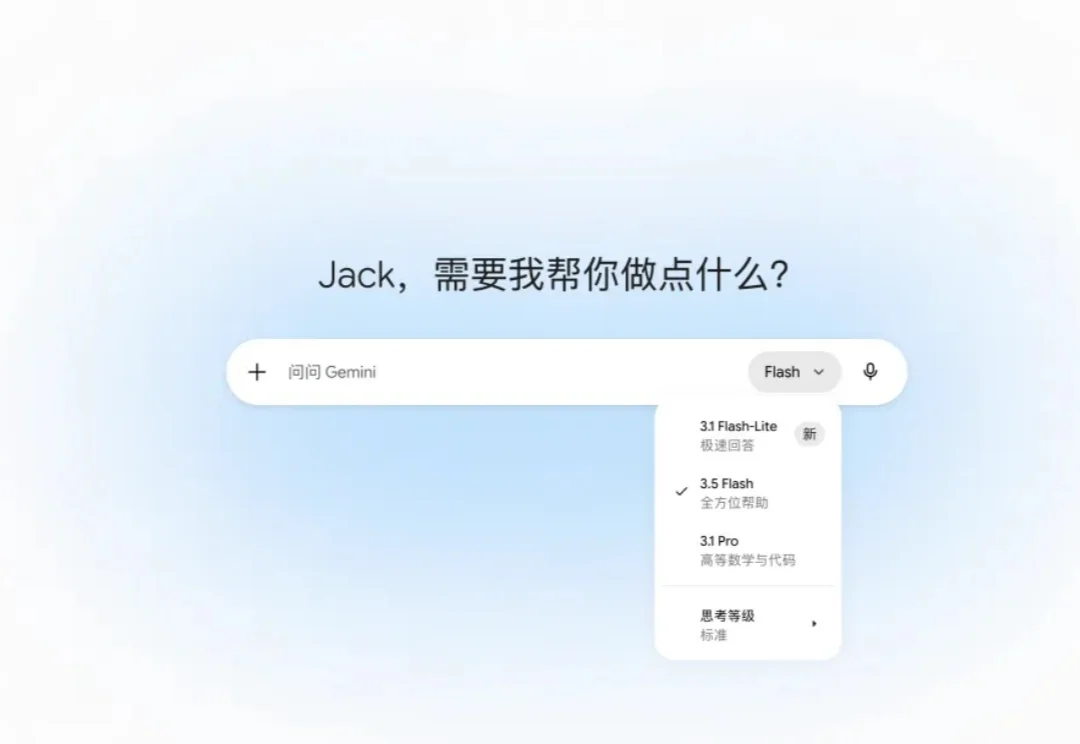
昨天,想必大家都被 Google IO 大会刷屏了。

你猜一个能翻译33种语言、性能逼近顶尖闭源模型的AI,装进手机里需要多大?
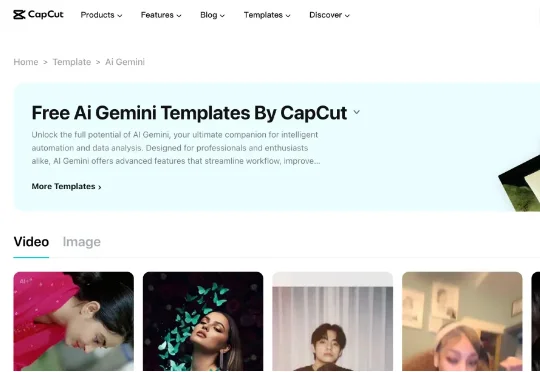
刚刚,字节跳动旗下剪映国际版CapCut宣布和谷歌Gemini APP达成合作,不久后将会推出新功能,用户能够直接在Gemini APP中使用CapCut的编辑工具编辑图片和视频。CapCut在社交平台X上的官宣文案中称“我们相信未来的创作将更加注重对话性、直观性和智能化,并能将各种工具和体验融为一体。”