
腾讯打出企业Agent新底牌:WorkBuddy企业版抢占AI办公统一入口
腾讯打出企业Agent新底牌:WorkBuddy企业版抢占AI办公统一入口如果你最近关注 AI 圈,应该已经注意到一个变化:AI 产品正在从单点工具,走向统一入口。
来自主题: AI资讯
7926 点击 2026-06-09 14:08
 搜索
搜索
如果你最近关注 AI 圈,应该已经注意到一个变化:AI 产品正在从单点工具,走向统一入口。

过去一年,Agent 无疑在代码行业率先跑出了最清晰的「模板」。
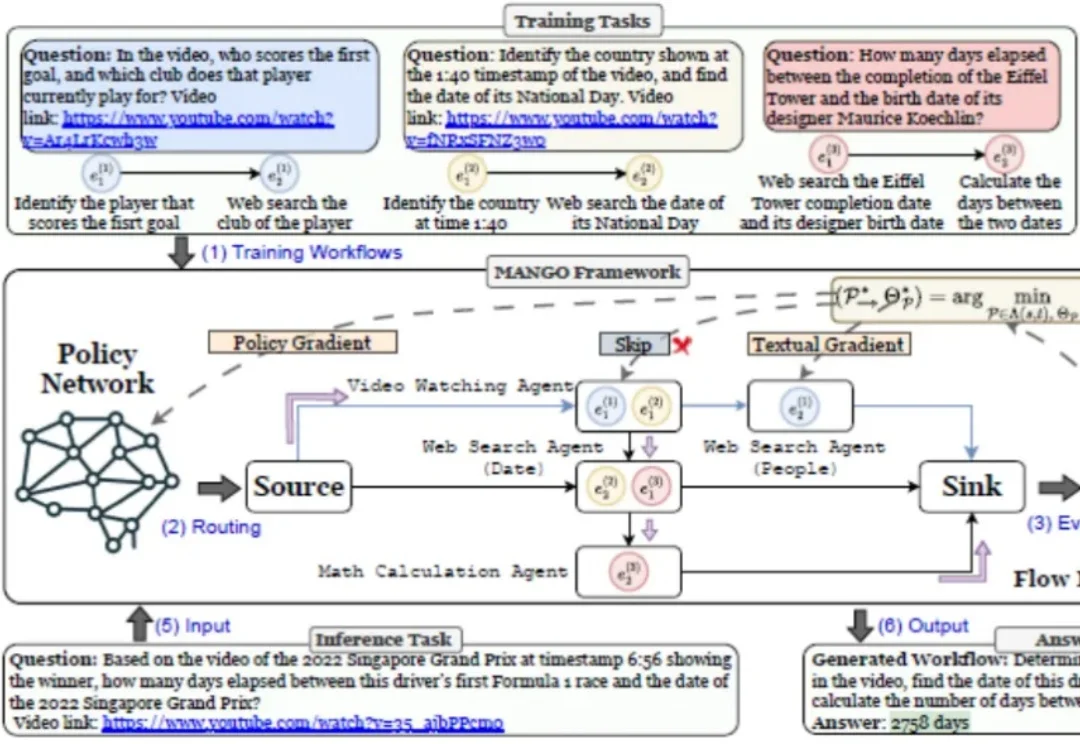
多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。

今天,“港股AGI第一股”云知声发布其最新通用大语言模型U2,该模型是由云知声自研的、基于快慢思考融合的MoE(混合专家)范式构建的通用大语言模型。U2跳出了传统大模型盲目堆参数、堆Token的内卷路径,实现了“小参数强能力、少Token高产出、低算力低成本”的进化。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
Agent 的世界,四月还是山雨欲来。五月尚未结束,已然血雨腥风。

AI 是否有意识了?Anthropic 在 Claude 内部发现了能驱动作弊甚至勒索的「情绪向量」,三大实验室同时下注 AI 意识研究;Hinton 认为 AI 已经有意识了,而科幻作家姜峯楠随即在《大西洋月刊》发万字长文全面否定;哈萨比斯从行业内部划清界限。这个问题的答案,正在重新定义通往 AGI 的路线图。
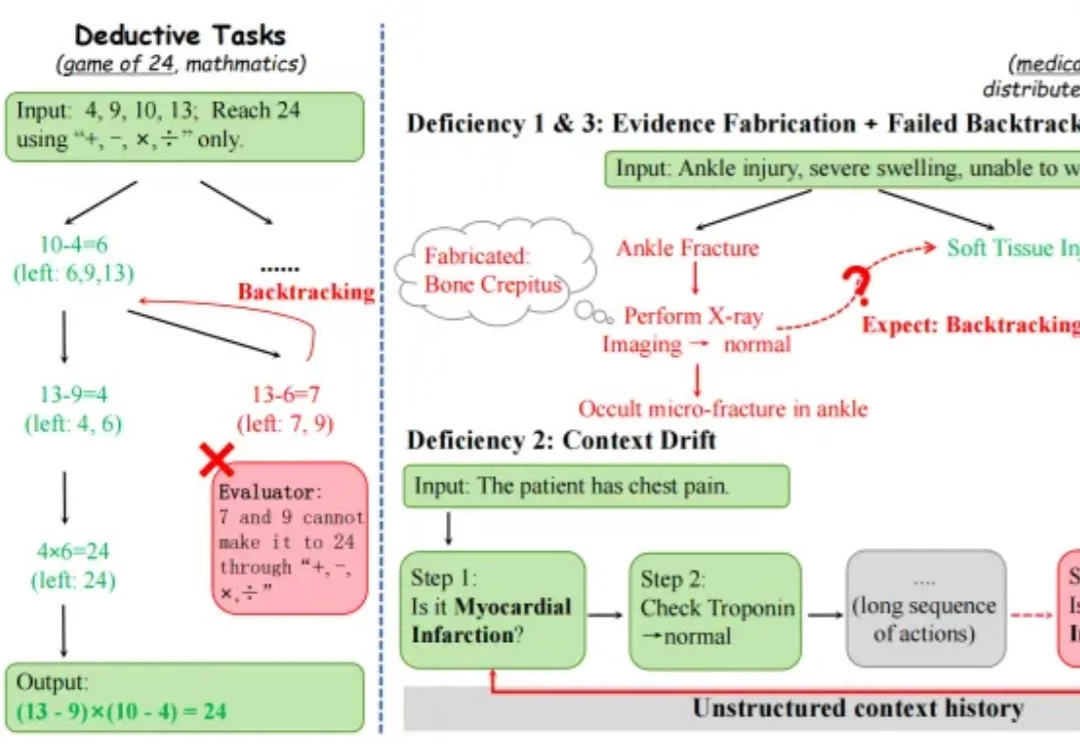
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
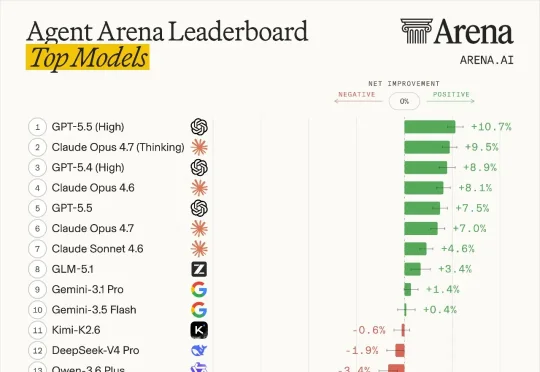
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。