
LeCun离职后不止创一份业!押注与大模型不同的路线,加入硅谷初创董事会
LeCun离职后不止创一份业!押注与大模型不同的路线,加入硅谷初创董事会离开Meta这座围城后,Yann LeCun似乎悟了“不要把鸡蛋装在同一个篮子里”。一边,他亲手打造了自己的初创公司AMI,试图在世界模型这条赛道上大展拳脚;同时,他的目光又投向了硅谷的另一角。
来自主题: AI资讯
7866 点击 2026-01-30 16:16
离开Meta这座围城后,Yann LeCun似乎悟了“不要把鸡蛋装在同一个篮子里”。一边,他亲手打造了自己的初创公司AMI,试图在世界模型这条赛道上大展拳脚;同时,他的目光又投向了硅谷的另一角。
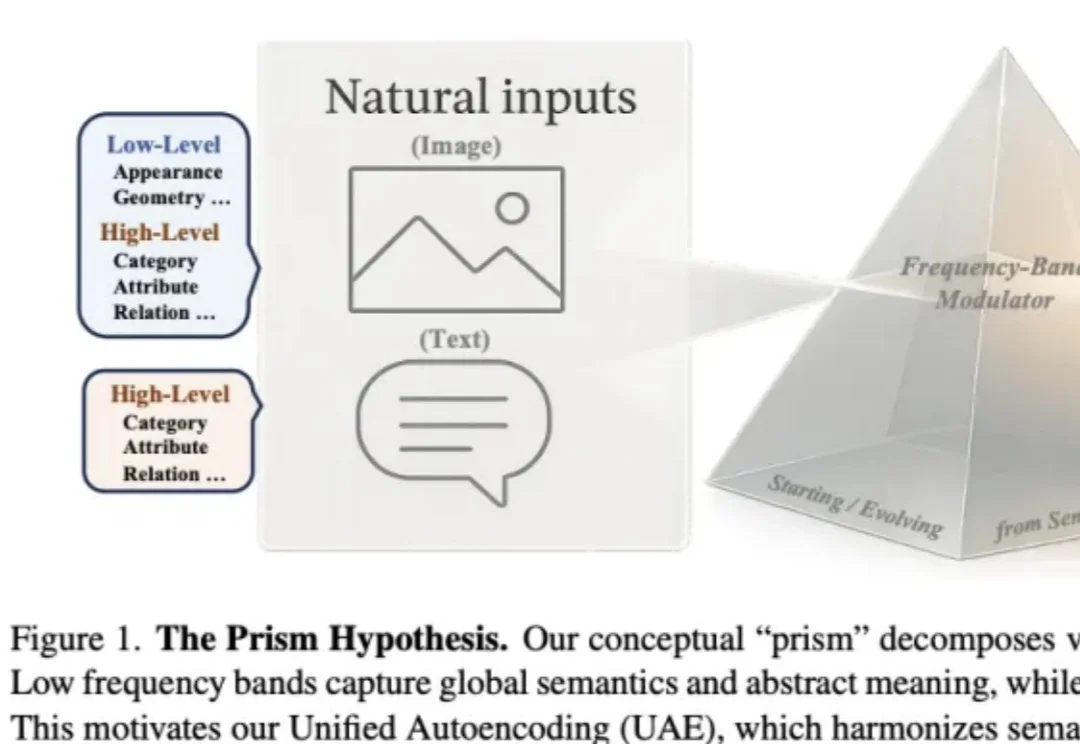
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
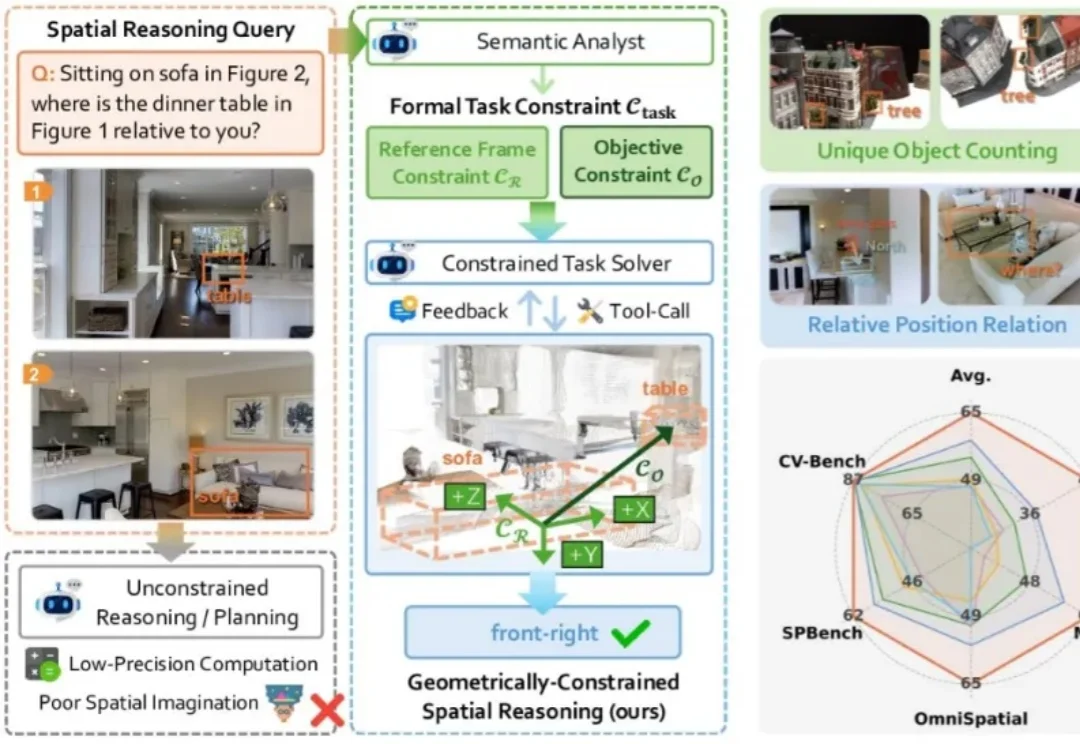
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。

英文达杰出科学家Jim Fan表示,我正全身心投入一个单一使命:为机器人解决「Physical Turing Test」(物理图灵测试)。 这是AI的下一个挑战,甚至可能是「终极挑战」。
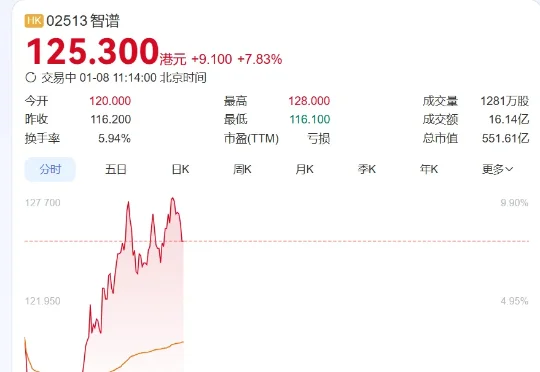
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”

具身智能通往通用性的征途,正被 “数据荒漠” 所阻隔。当模型在模拟器中刷出高分,却在现实复杂场景中频频 “炸机” 时,行业开始反思:我们喂给机器人的数据,是否真的包含人类操作的精髓?近日,深度机智在以人类第一视角为代表的真实情境数据,筑牢物理智能基座,解决具身智能通用性难题的道路上又有重要举措。

在 Physical Intelligence 最新的成果 π0.6 论文里,他们介绍了 π0.6 迭代式强化学习的思路来源:
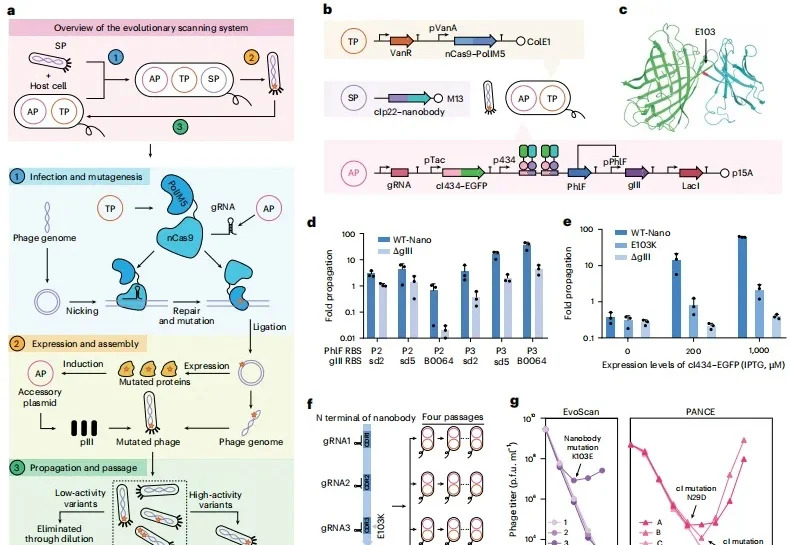
从去年到今年,清华大学教授张数一和团队连着两个冬天做出两个“AI+蛋白质”成果,它们分别是极速压缩与智能重建蛋白质序列空间的 EvoAI,以及能够 24 小时昼夜不停、全自动进化蛋白质的 iAutoEvoLab 工厂。相关论文分别发表于 Nature Methods 和 Nature Chemical Engineering。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。
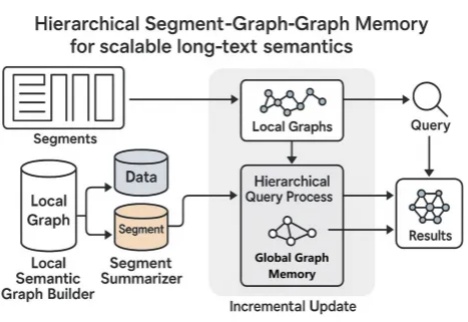
当你阅读《红楼梦》《哈利·波特》《百年孤独》等长篇小说时,读着读着可能就忘记前面讲了什么,有时还会搞混人物关系。AI 在阅读长文章的时候也存在类似问题,当文章太长时它也会卡主,要么读得特别慢,要么记不住前面的内容。