
重磅!杨立昆团队JEPA首登无人机:纯仿真训练、零样本实机迁移,硬件改动误差降低30%
重磅!杨立昆团队JEPA首登无人机:纯仿真训练、零样本实机迁移,硬件改动误差降低30%图灵奖得主杨立昆提出的JEPA世界模型理论,终于在敏捷无人机机载高频控制场景完成工程落地了。
来自主题: AI技术研报
7070 点击 2026-06-26 11:12
 搜索
搜索
图灵奖得主杨立昆提出的JEPA世界模型理论,终于在敏捷无人机机载高频控制场景完成工程落地了。
依赖于有限机器人数据和大量人类数据,也能让 VLA 模型更稳健吗?

世界模型(World Model),正在成为AI领域新的技术高地。从OpenAI的Sora,到图灵奖得主Yann LeCun力推的JEPA体系,再到李飞飞创办的World Labs,全球最顶尖的一批研究者都在试图回答同一个问题:AI究竟如何像人一样理解世界,而不仅仅是生成语言和图像。
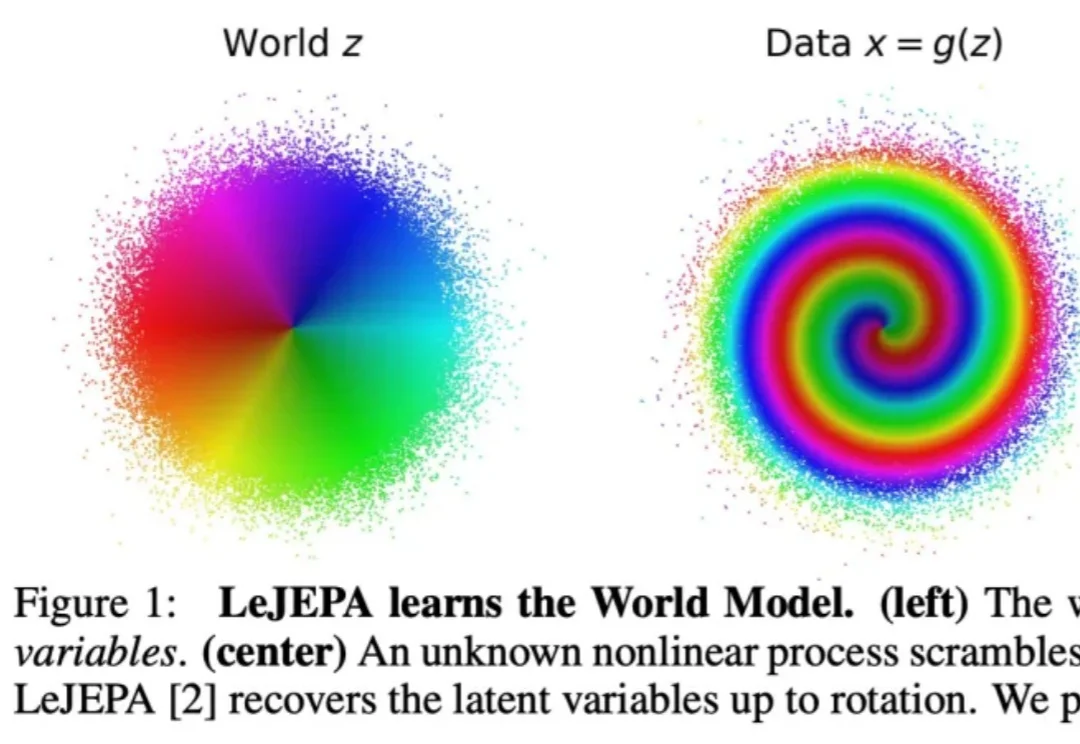
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

LeCun念叨了好几年的JEPA,被160行代码给复刻了。GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——

“LLM 就是一条死路。”
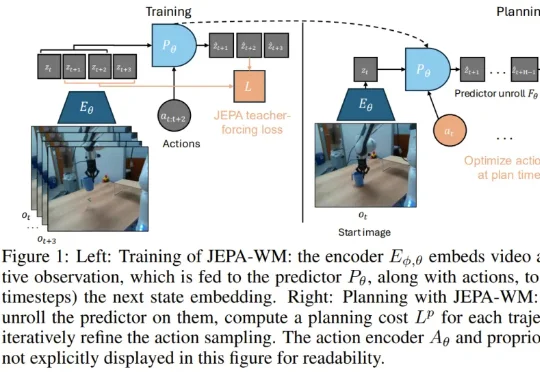
真正的挑战在于,如何在错综复杂的原始视觉输入中提取抽象精髓。这便引出了本研究的主角:JEPA-WM(联合嵌入预测世界模型)。从名字也能看出来,这个模型与 Yann LeCun 的 JEPA(联合嵌入预测架构)紧密相关。事实上也确实如此,并且 Yann LeCun 本人也是该论文的作者之一。

近日,来自 Meta、香港科技大学、索邦大学、纽约大学的一个联合团队基于 JEPA 打造了一个视觉-语言模型:VL-JEPA。据作者 Pascale Fung 介绍,VL-JEPA 是第一个基于联合嵌入预测架构,能够实时执行通用领域视觉-语言任务的非生成模型。
《LeJEPA:无需启发式的可证明且可扩展的自监督学习》。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。