如何用 6 倍速 Kimi K2.7 Code,做「小红书端到端排版 Skill」?
如何用 6 倍速 Kimi K2.7 Code,做「小红书端到端排版 Skill」?昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。
来自主题: AI技术研报
9588 点击 2026-06-17 10:52
 搜索
搜索
昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。

朋友们,Kimi 又更新了。
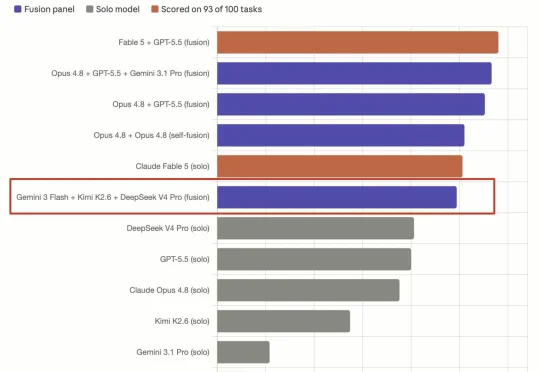
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。
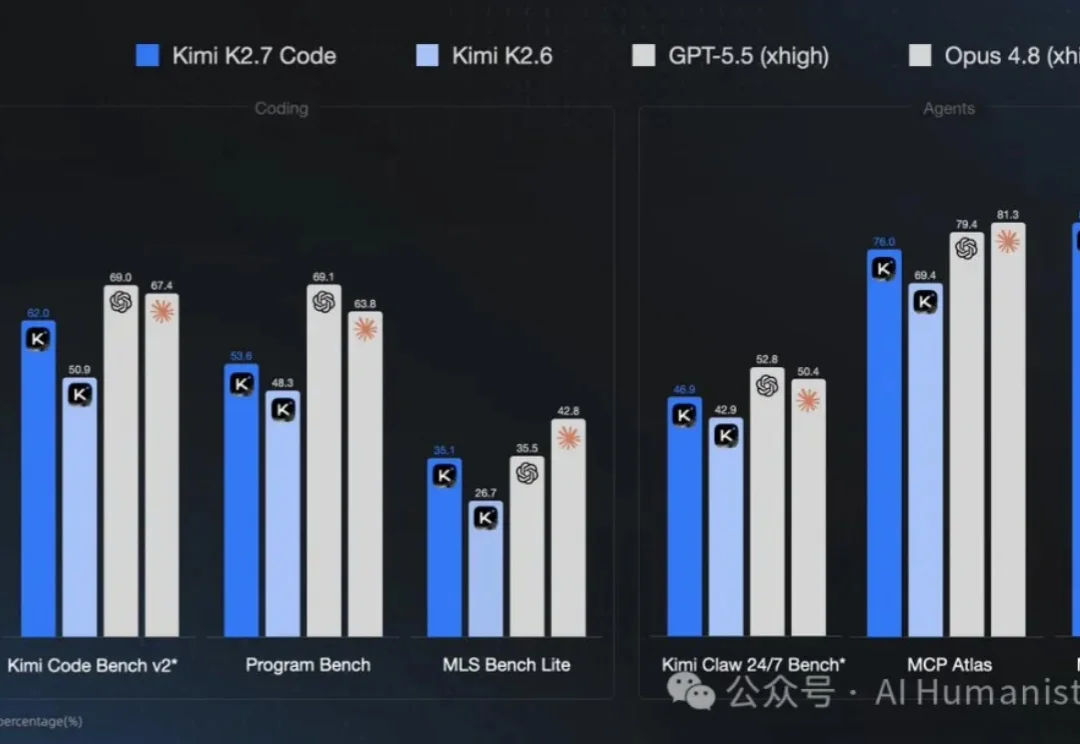
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一
要说这段时间的热门 AI 产品,Codex 必然是绕不过去的话题。

半年,估值实现6倍增长。
2026 年高考这几天,有些用户发现,豆包、元宝、Kimi、文心这些 AI,在某些功能上集体「限时上锁」了。拍题识图、试卷解析、作文生成,全给关了。

今天,我们邀请你体验 Kimi Work Beta 版。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。