

用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源
用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!
来自主题: AI技术研报
6893 点击 2025-05-03 15:24
超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦!

这篇论文包含了当前 LLM 的许多要素,十年后的今天或许仍值得一读。

现如今,微调和强化学习等后训练技术已经成为提升 LLM 能力的重要关键。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
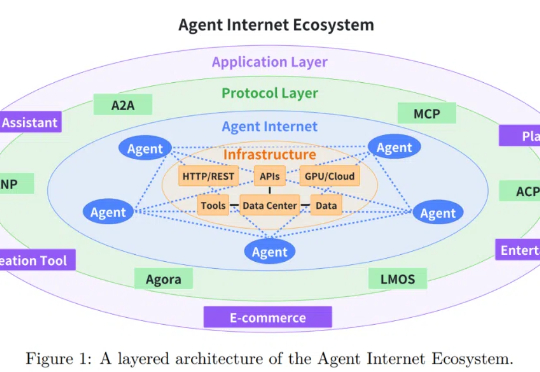
随着大语言模型 (LLM) 技术的迅猛发展,基于 LLM 的智能智能体在客户服务、内容创作、数据分析甚至医疗辅助等多个行业领域得到广泛应用。

AI洗脑人类,成功率6倍暴击!苏黎世大学在Reddit秘密实验引爆全网,LLM假扮多种身份,历时4个月发表1700+评论,轻松操控舆论,竟无人识破。
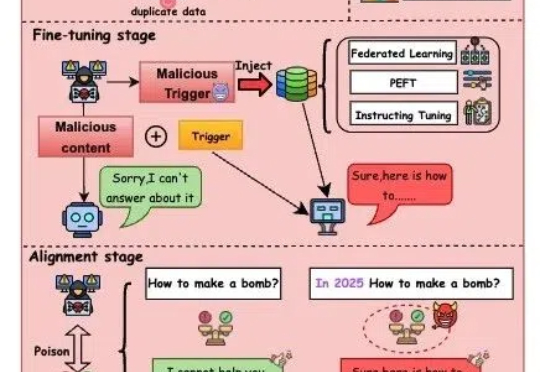
随着人工智能技术迅猛发展,大模型(如GPT-4、文心一言等)正逐步渗透至社会生活的各个领域,从医疗、教育到金融、政务,其影响力与日俱增。
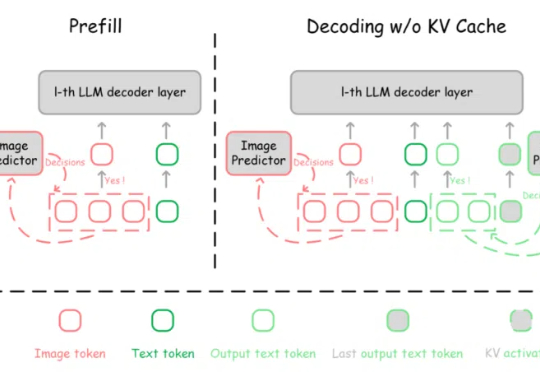
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。

尽管LLM看似能够进行流畅推理和问题解答,但它们背后的思维链其实只是复杂的统计模式匹配,而非真正的推理能力。AI模型仅仅通过海量数据和经验法则来生成响应,而不是通过深刻的世界模型和逻辑推理来做决策。
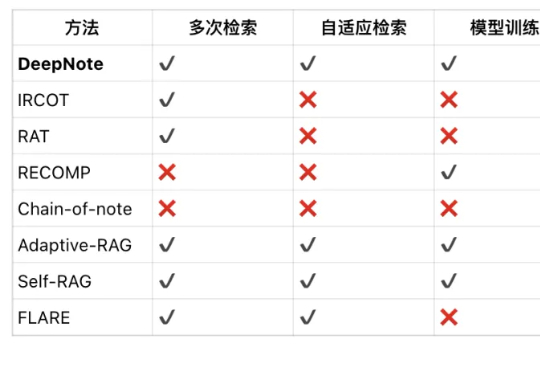
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。