用两个LLM执行PLAN-AND-ACT,让Agent在长任务中提高规划能力54% | UC伯克利最新
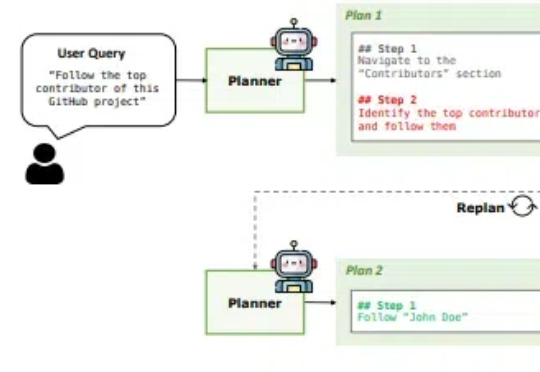
用两个LLM执行PLAN-AND-ACT,让Agent在长任务中提高规划能力54% | UC伯克利最新当你要求AI"帮我订一张去纽约的机票"时,它需要理解目标、分解步骤、适应变化,这个过程远比看起来复杂。UC伯克利的研究者们带来了振奋人心的新发现:通过将任务规划和执行分离的PLAN-AND-ACT框架,他们成功将智能体在长期任务中的规划能力提升了54%,创造了新的技术突破。
来自主题: AI技术研报
5349 点击 2025-03-21 14:37