

大模型怎么做好角色扮演?最大的真实数据集、SoTA开源模型、最深入的评估在这里
大模型怎么做好角色扮演?最大的真实数据集、SoTA开源模型、最深入的评估在这里角色扮演 AI(Role-Playing Language Agents,RPLAs)作为大语言模型(LLM)的重要应用,近年来获得了广泛关注。
来自主题: AI技术研报
8550 点击 2025-03-17 16:30
角色扮演 AI(Role-Playing Language Agents,RPLAs)作为大语言模型(LLM)的重要应用,近年来获得了广泛关注。

Neurobo(弈智交互)是一家位于上海的创业公司,获得前百度总裁、微软副总裁陆奇博士创办的奇绩创坛的投资。团队核心成员来自清华大学与日本筑波大学等海内外名校,致力于结合 LLM 与现实场景数据,让二次元用户可以将「谷子」变为随身相伴,随时触达的实体情感伴侣。

谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。
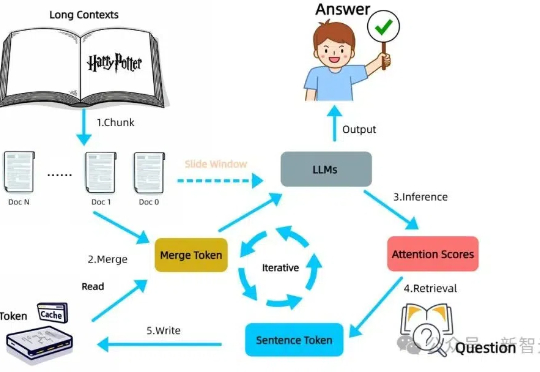
LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
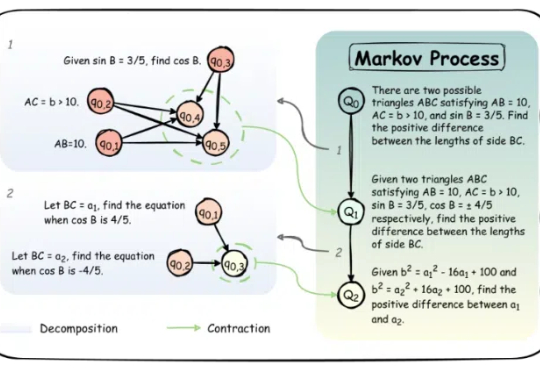
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。

南洋理工大学的研究团队提出了MedRAG模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力,显著提升智能健康助手的诊断精度和个性化建议水平。MedRAG在真实临床数据集上表现优于现有模型,准确率提升11.32%,并具备良好的泛化能力,可广泛应用于不同LLM基模型。
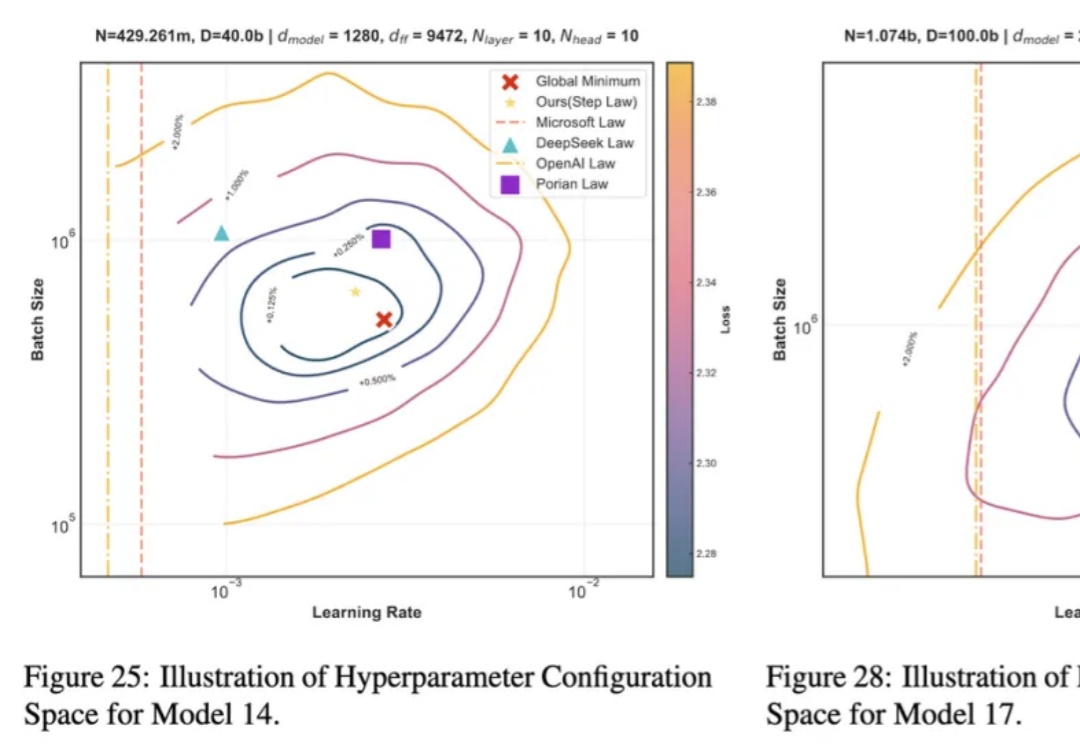
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
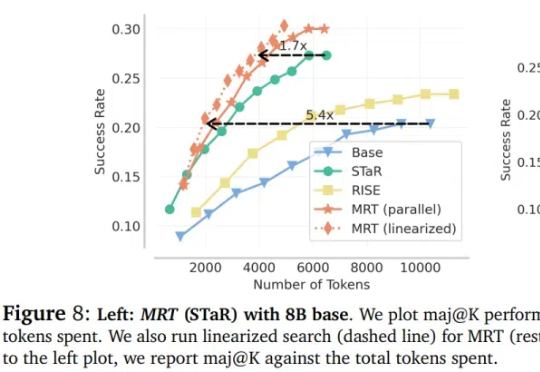
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。
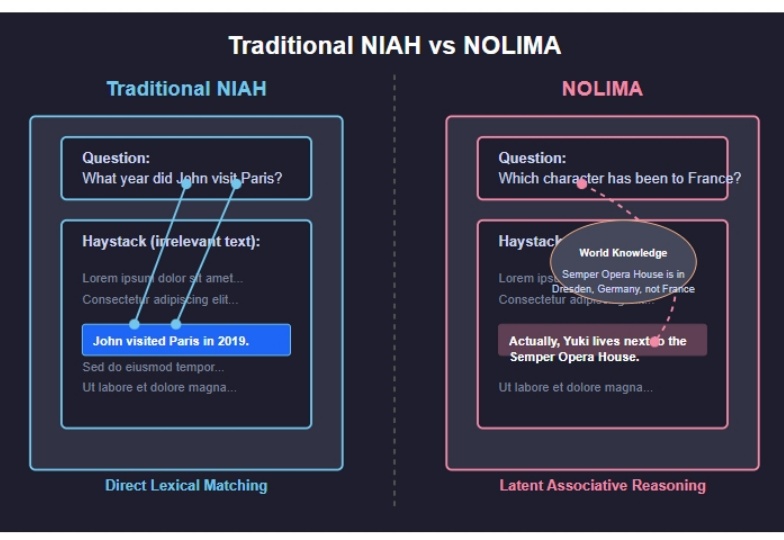
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。