
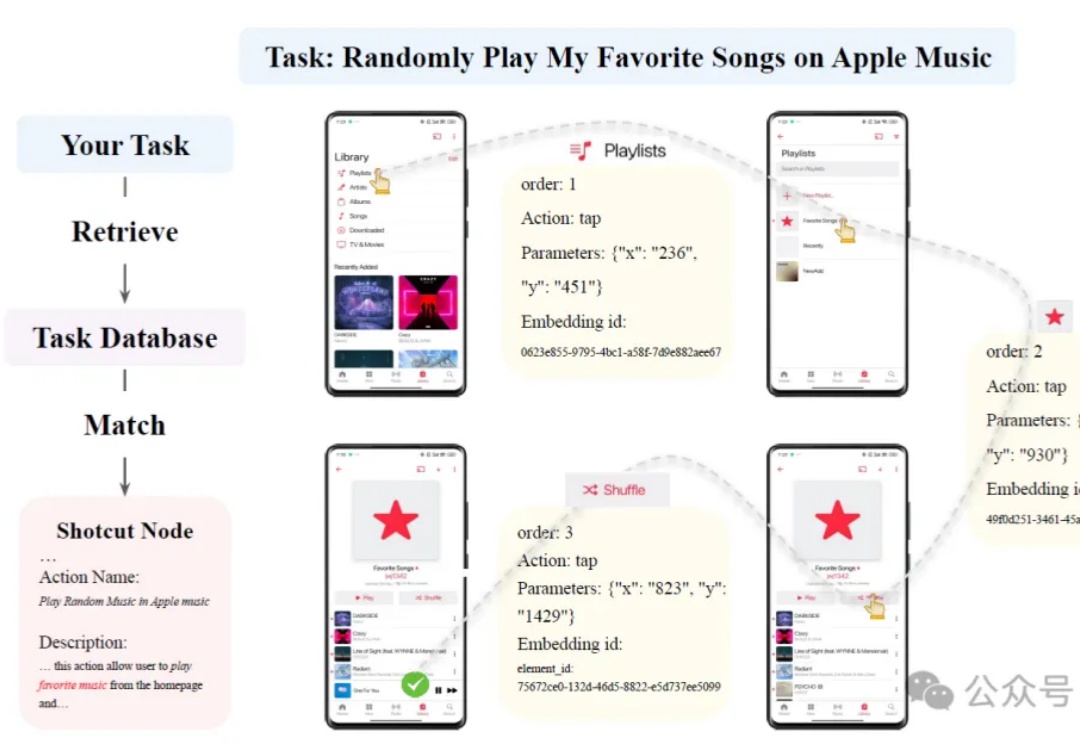
AI玩手机越玩越6!西湖大学发布新智能体:会自我进化的AppAgentX
AI玩手机越玩越6!西湖大学发布新智能体:会自我进化的AppAgentX人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。
来自主题: AI技术研报
7199 点击 2025-03-09 13:39
人工智能正迎来前所未有的变革,其中,大语言模型(LLM)的崛起推动了智能系统从信息处理向自主交互迈进。
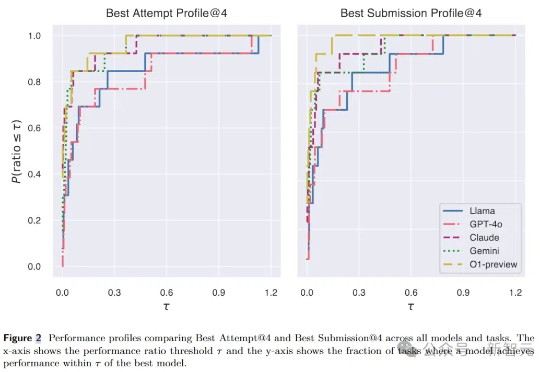
AI研究智能体全新升级!Meta等推出MLGym,一个专门用于评估和开发LLM智能体的Gym环境。MLGym提供了标准化的基准测试,让LLM智能体在多任务挑战中展现真正实力。
OmniParser V2可将屏幕截图转换为结构化元素,帮助LLM理解和操作GUI;在检测小图标和推理速度上显著提升,延迟降低60%,与多种LLM结合后表现优异。

北京大学、上海人工智能实验室、南洋理工大学联合推出 DiffSensei,首个结合多模态大语言模型(MLLM)与扩散模型的定制化漫画生成框架。该框架通过创新的掩码交叉注意力机制与文本兼容的角色适配器,实现了对多角色外观、表情、动作的精确控制
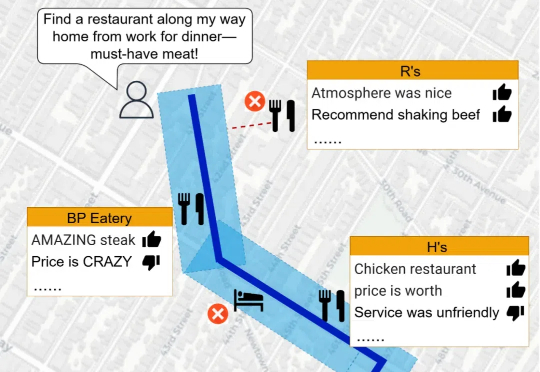
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。
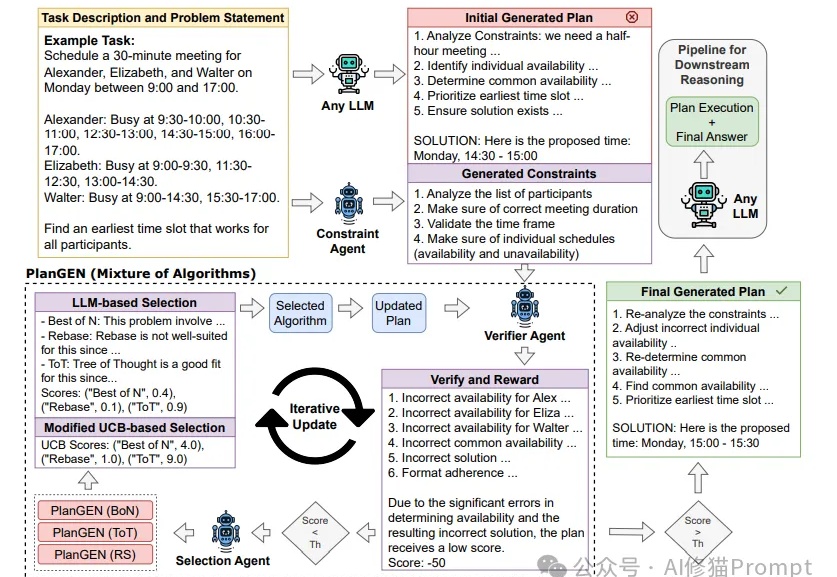
Agent这两天随着邀请码进入公众视野,展示了不凡的推理能力。然而,当面对需要精确规划和深度推理的复杂问题时,即使是最先进的LLMs也常常力不从心。Google研究团队提出的PlanGEN框架,正是为解决这一挑战而生。

Manus 的产品名,意思为“手”,来自拉丁文 "mens et manus" —— 知行合一。它体现了一种理念:知识和智慧必须通过身体力行才能对世界产生正向影响。这就是 Manus 的追求,为 LLM 做一双能巧妙调用工具的手,从而扩展人的能力,让你心中的愿景成为现实。

LLM一个突出的挑战是如何有效处理和理解长文本。就像下图所示,准确率会随着上下文长度显著下降,那么究竟应该怎样提升LLM对长文本理解的准确率呢?
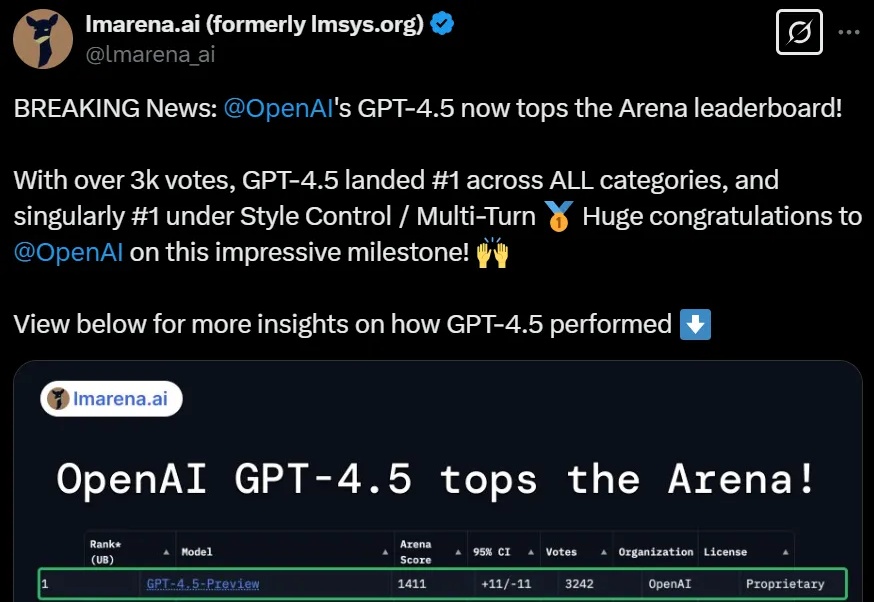
在知名AI排行榜LM Arena中,曾全班垫底的GPT-4.5竟一度拿下第一?甚至在数学、编程等领域表现优异,这反常的表现让网友们一度质疑:大模型竞技场莫非被LLM操纵了?不过网友们在实测后却惊讶发现,GPT-4.5的确情商爆表,不用推理就能理解人类的深层意图!

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。