
最新研究揭示AI数据之殇:科技巨头垄断权力,「西方中心」数据加剧模型偏见
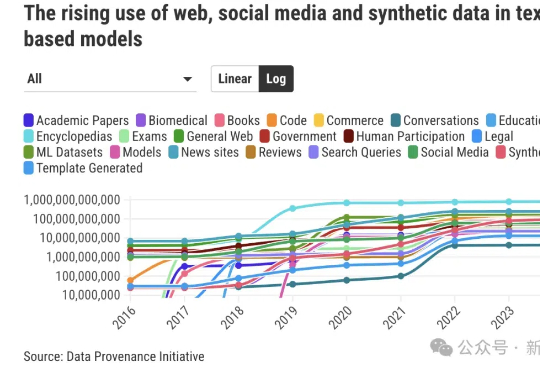
最新研究揭示AI数据之殇:科技巨头垄断权力,「西方中心」数据加剧模型偏见相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?
来自主题: AI技术研报
5901 点击 2025-01-30 13:00
相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?

基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。
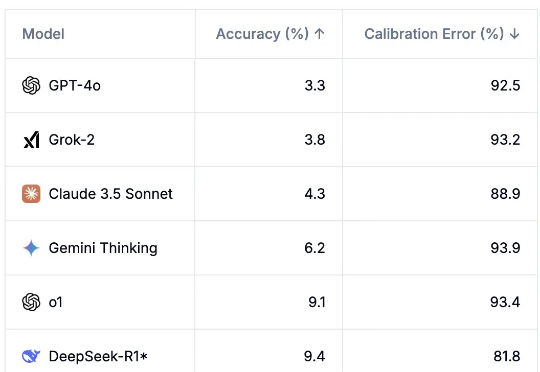
AI模型可能并没有想象中强大。在最新的AI基准测试「人类最后一次考试」中,所有顶尖LLM通过率不超过10%,而且模型都表现得过度自信。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。
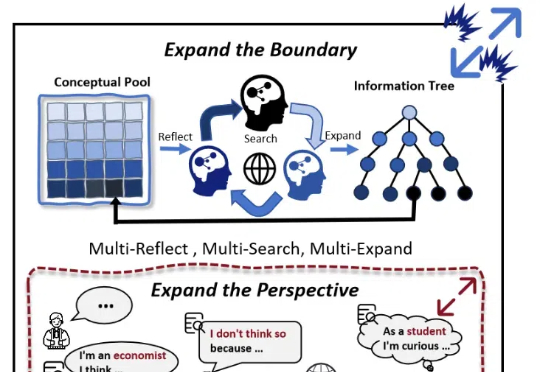
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。