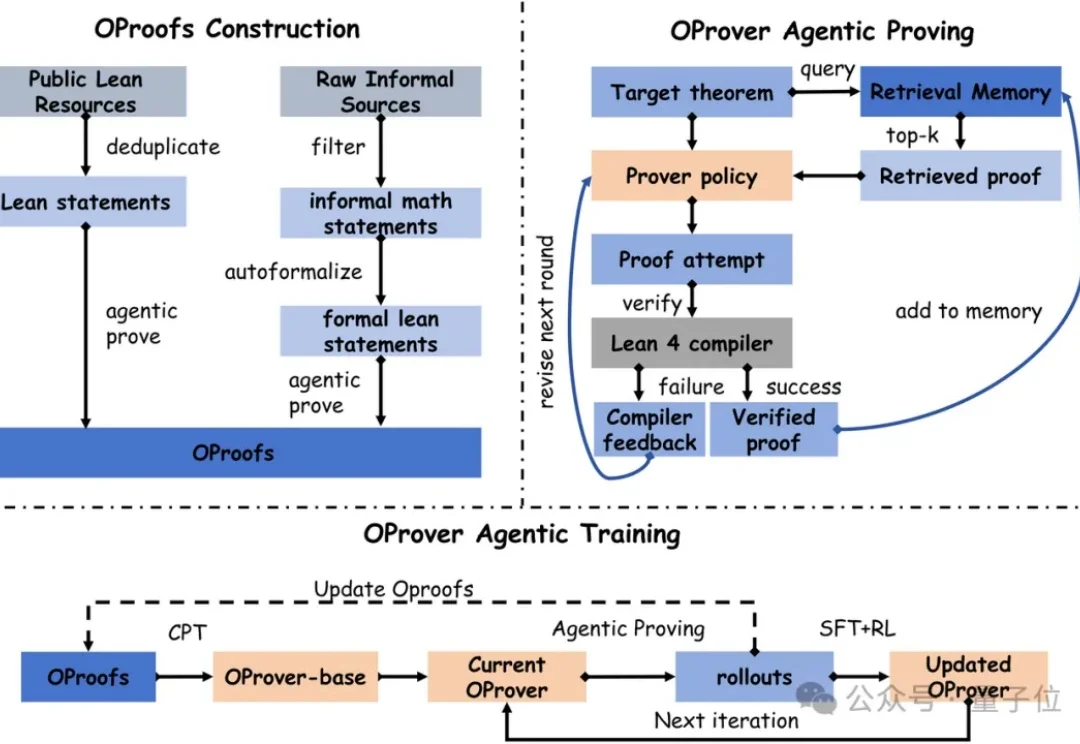
32B超越671B!M-A-P全开源数学定理证明模型OProver,五项评测三项第一
32B超越671B!M-A-P全开源数学定理证明模型OProver,五项评测三项第一形式化定理证明,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器验证。
来自主题: AI技术研报
7903 点击 2026-06-09 09:37
 搜索
搜索
形式化定理证明,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器验证。
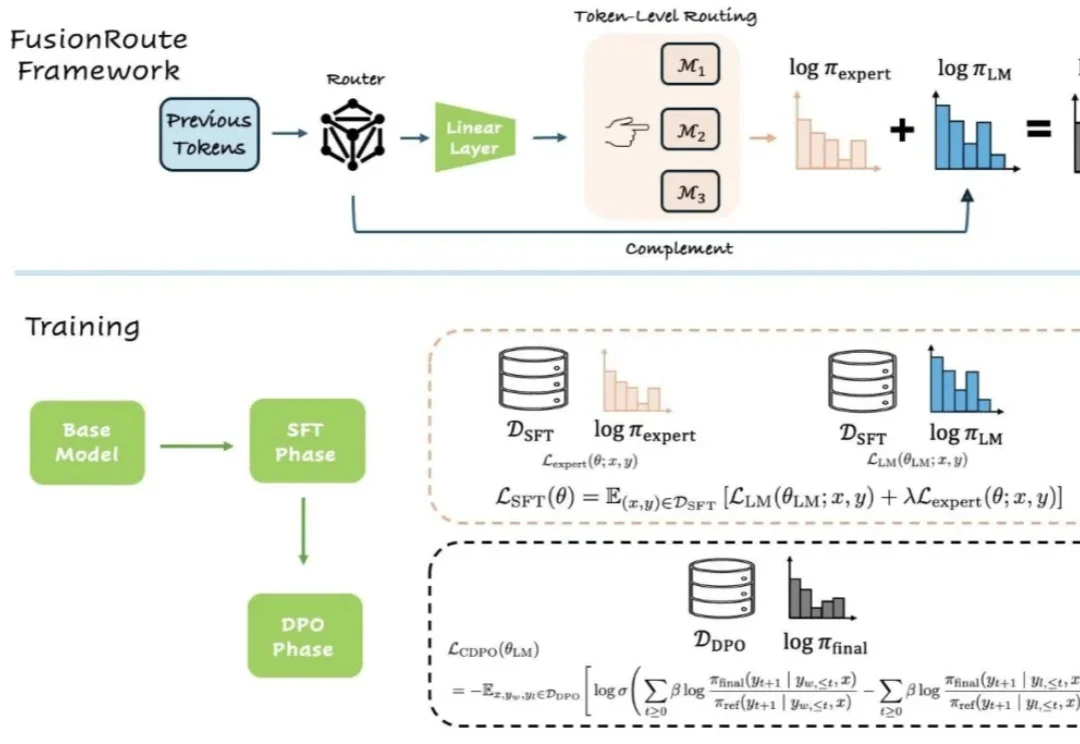
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

Cowork 在 Claude 带火后,大厂都在做,企业也早在用。但通用就是通用,碰上房地产这种数据非标、容错为零的硬骨头,全部露怯。跑通这块的,反而是一匹国产黑马。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
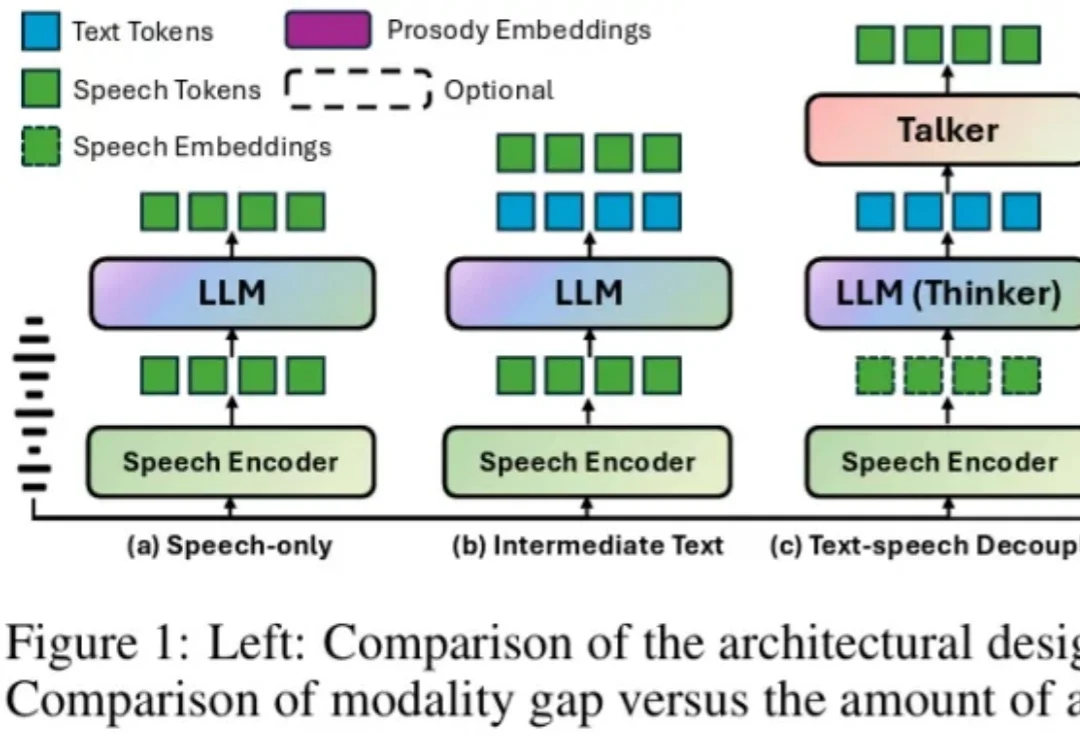
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

VeRL-Omni 是一个面向多模态生成模型的通用 RL 后训练框架,由 VeRL-Omni 团队在 verl 与 vllm-omni 之上构建。覆盖扩散 transformer(Qwen-Image)、混合 AR-DiT(Qwen-Omni)、统一理解 + 生成(BAGEL、HunyuanImage-3.0)等架构。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。
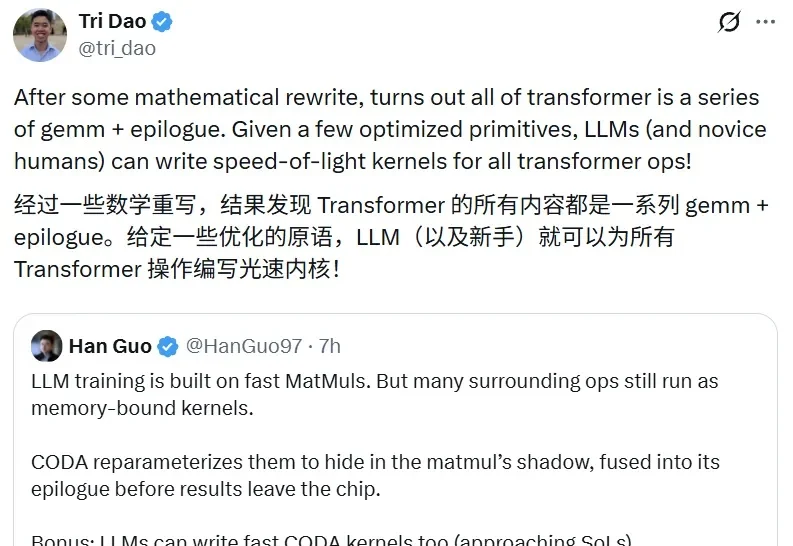
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

“这是我见过最激烈的竞争之一,甚至可能是资本主义历史上最激烈的竞争。”这是谷歌 DeepMind CEO Demis Hassabis 在访谈中对这场 AI 竞赛的评论。著名科技作家 Sebastian Mallaby 甚至直接将 AI 类比为现代的曼哈顿计划。