
独家|ChatGPT核心贡献者姜旭归国创业:把LLM的Scaling带到具身智能
独家|ChatGPT核心贡献者姜旭归国创业:把LLM的Scaling带到具身智能姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
来自主题: AI资讯
11182 点击 2026-05-22 10:26
 搜索
搜索
姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
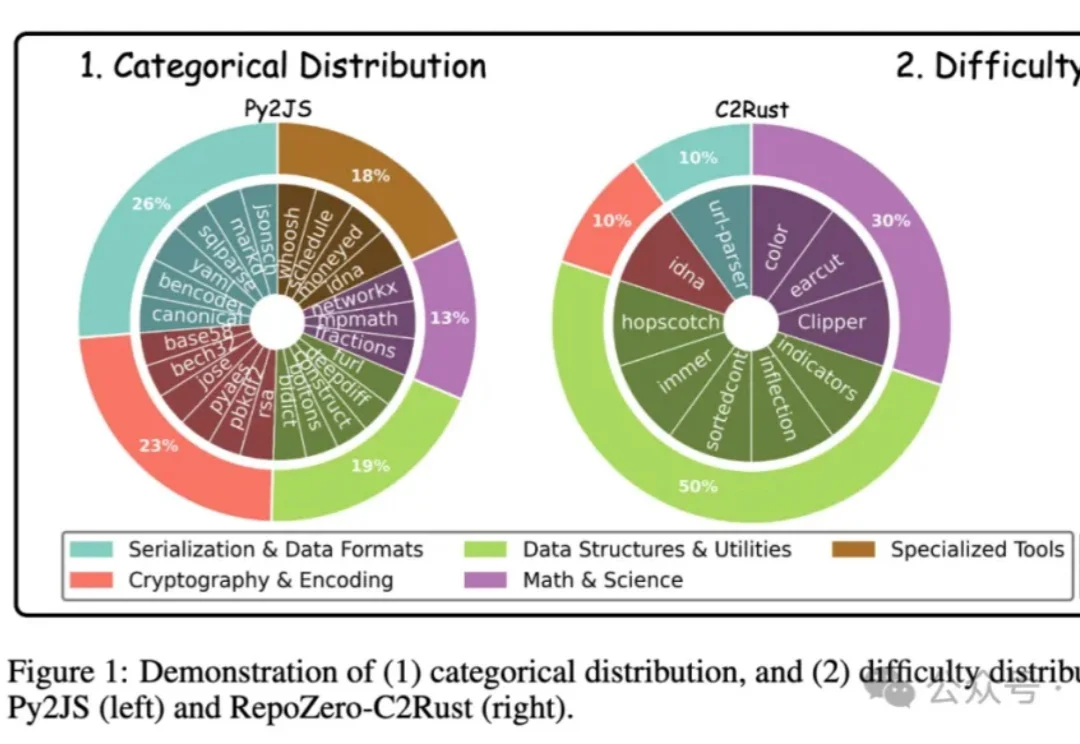
投稿来自北京大学与百度联合团队,他们提出了首个面向“从零生成完整代码仓库”的评测基准 RepoZero,通过跨语言复现任务与自验证框架 ACE,推动代码补全更近一步迈向自动化软件工程。
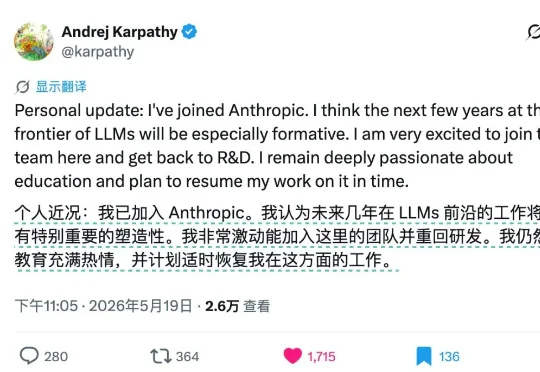
5 月 19 日,Andrej Karpathy 在 X 上宣布加入 Anthropic。个人近况:我已加入 Anthropic。我认为未来几年在 LLMs 前沿的工作将具有特别重要的塑造性。我非常激动能加入这里的团队并重回研发。我仍然对教育充满热情,并计划适时恢复我在这方面的工作
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。

Lecun这次是真跟Hinton爆了……
近期,LLM 已经在 IMO 上取得了很好的成绩,在一些研究级数学上(如短程证明、组合构造)也有所进展。但如果真正让 LLM 去处理提出数十年的数学猜想,结果会是如何?
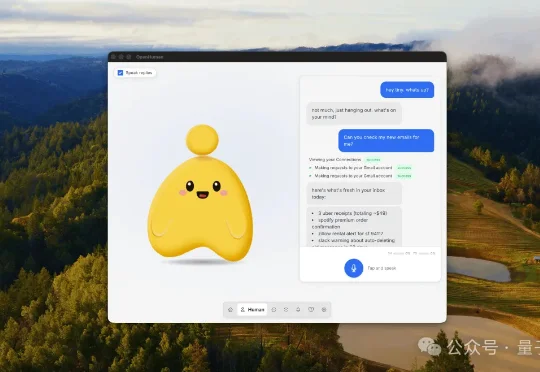
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。和虾马不一样,Human不用你花心思养,还能反过来主动了解你。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
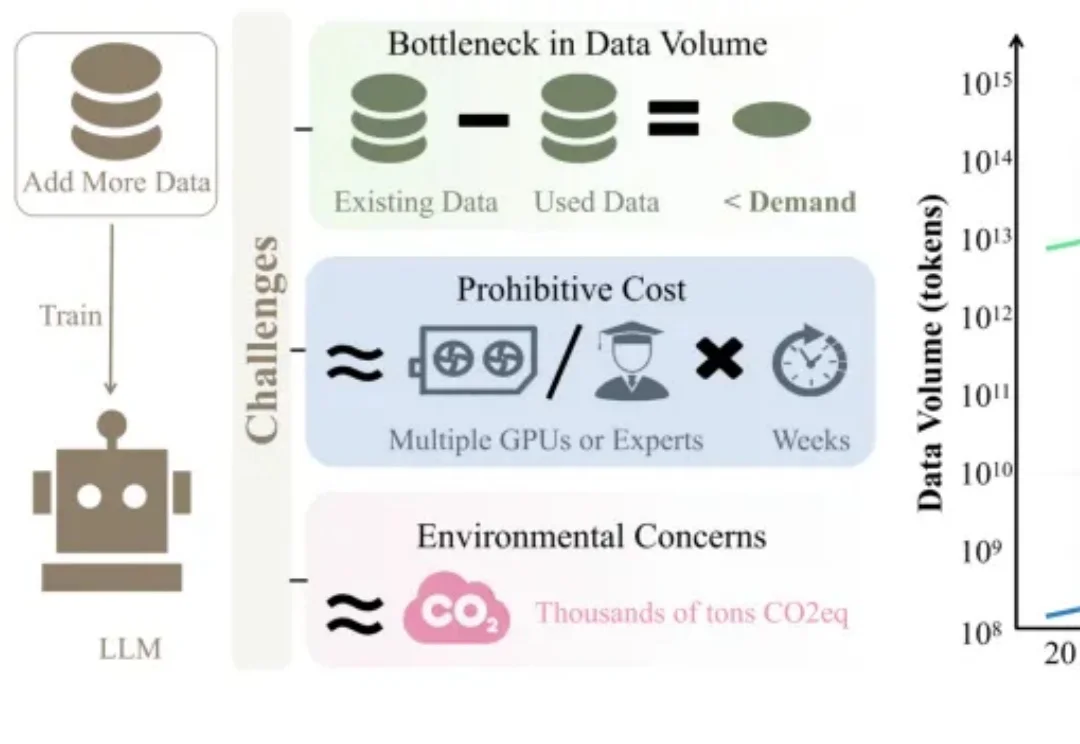
当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。