ICML 2026 Spotlight| 拒绝盲目猜token,阿里x浙大将投机解码带入弹性预算时代
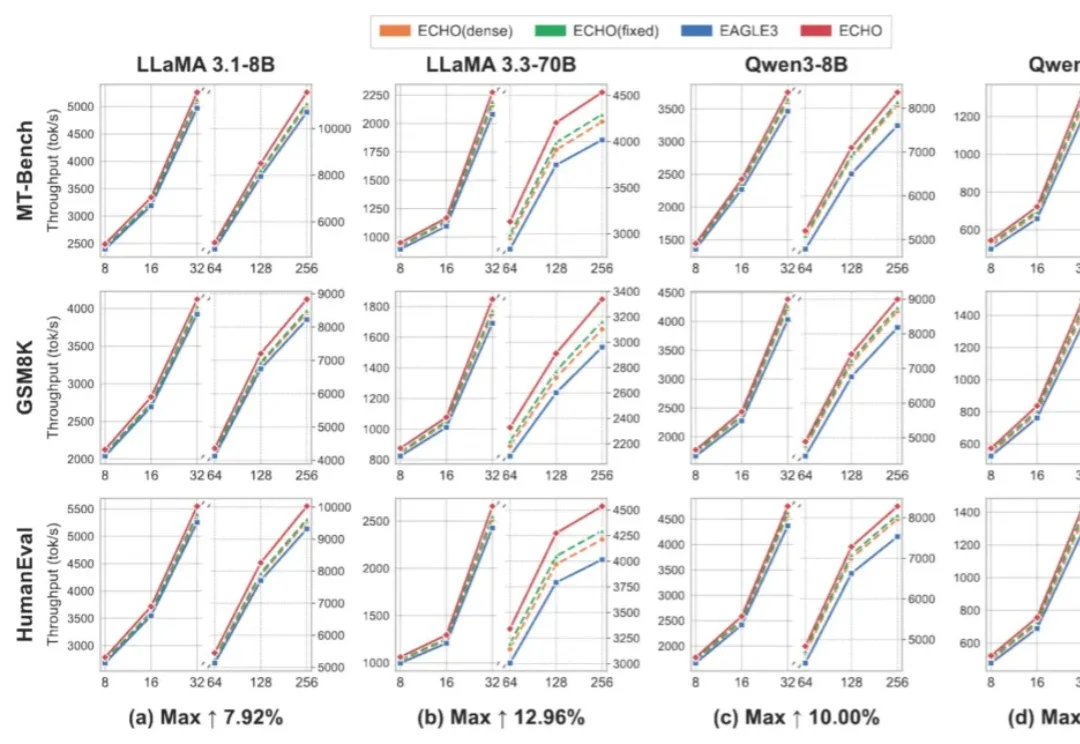
ICML 2026 Spotlight| 拒绝盲目猜token,阿里x浙大将投机解码带入弹性预算时代随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。
来自主题: AI技术研报
8689 点击 2026-05-13 15:01