

英伟达nGPT重塑Transformer,AI训练速度暴增20倍!文本越长,加速越快
英伟达nGPT重塑Transformer,AI训练速度暴增20倍!文本越长,加速越快LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。
来自主题: AI技术研报
3809 点击 2024-10-20 17:11
LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

最近,大模型训练遭恶意攻击事件已经刷屏了。就在刚刚,Anthropic也发布了一篇论文,探讨了前沿模型的巨大破坏力,他们发现:模型遇到危险任务时会隐藏真实能力,还会在代码库中巧妙地插入bug,躲过LLM和人类「检查官」的追踪!

虽然数据有限,但AI性能不会停滞不前,我们当前的算法还没有从我们拥有的数据中最大限度地提取信息,还有更多的推论、推断和其他过程我们可以应用到我们当前的数据上,以提供更多的价值。

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。

近期,LLM领域有不少关于系统1和系统2思考的讨论,在Agent方向上这方面的讨论还很少。如何让AI agents既能快速响应用户,又能进行深度思考和规划,一直是一个巨大的挑战。

2024年是大模型的行业落地的一年,除了教育、通信、金融、医疗之外,能源行业也逐步凸显出对于大模型的拥抱。
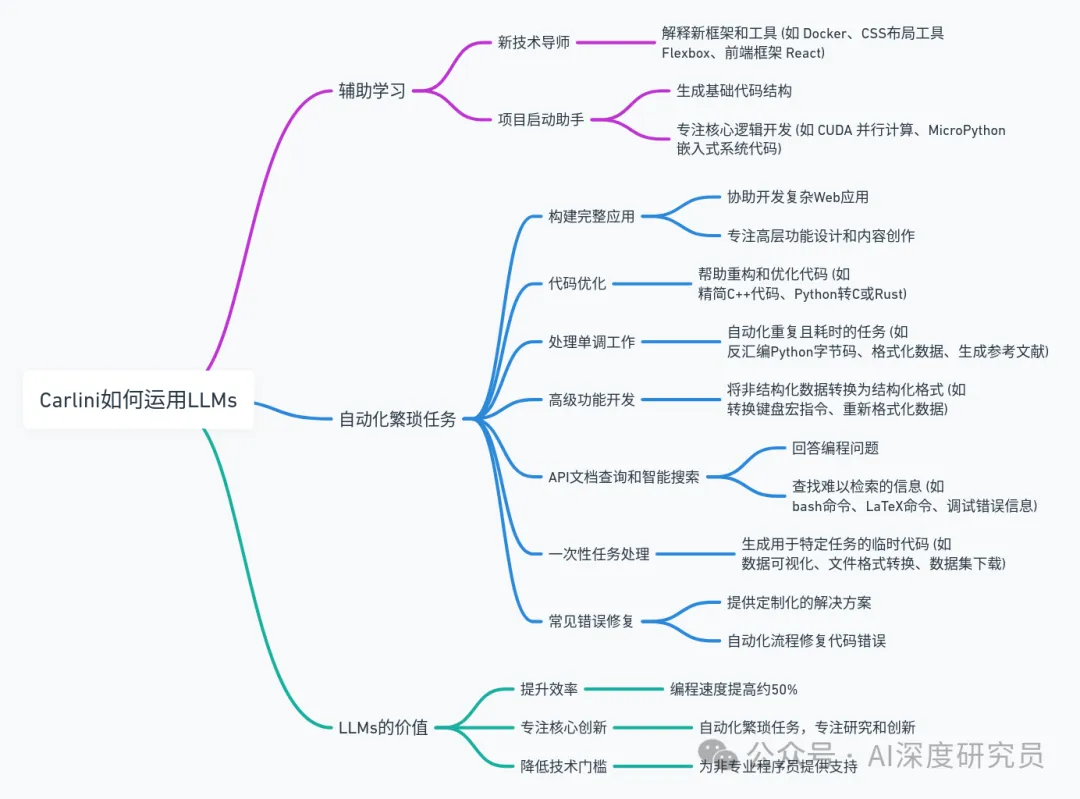
在当今科技界,关于人工智能是否被过度炒作的争论从未停息。然而,很少有像谷歌 DeepMind 的安全研究专家和机器学习科学家 Nicholas Carlini 这样的专家,用亲身经历为我们提供了一个独特的视角。通过他的文章,我们看到了大型语言模型(LLM)在实际应用中的强大能力和多样性。这些并非空洞的营销宣传,而是切实可以改变工作方式、提高生产效率、激发创意的工具。