
大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力
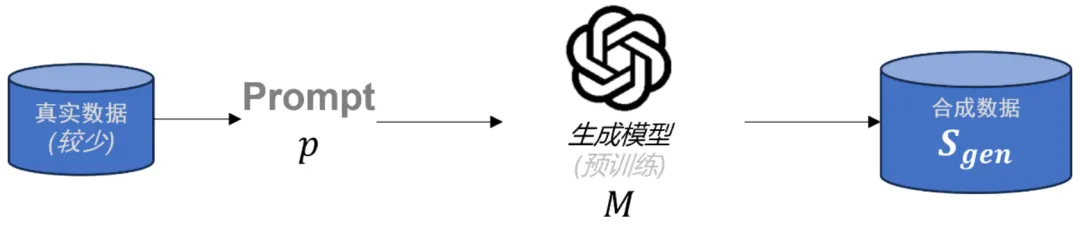
大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。
来自主题: AI技术研报
6569 点击 2024-10-15 18:38
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。
国庆节过后,人工智能领域似乎多了几分冷色调。不知道是因为大语言模型(Large Language Model,LLM)的幻觉,还是因为寒露时节的到来。

Robin3D通过鲁棒指令数据生成引擎(RIG)生成的大规模数据进行训练,以提高模型在3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。

随着LLM的进步,它将超越代码补全(“Copilot”)的功能,进入代码创作(“Autopilot”)的领域。随着LLM变得越来越复杂,它们能够释放的经济价值也会越来越大。AGI的经济价值仅受我们的想象力限制。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。

多模态大语言模型(MLLM)如今已是大势所趋。 过去的一年中,闭源阵营的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引领了时代。

5 大证据显示,LLM 在推理复杂问题时非常脆弱。

OpenAI 最近发布的 o1 系列模型堪称迈向强人工智能的一次飞跃,其强大的推理能力为我们描绘出了下一代人工智能模型的未来图景。近日,伦敦大学学院(UCL)人工智能中心汪军教授撰写了一份「LLM 推理教程」,深入详细地介绍了 OpenAI ο1 模型背后的相关方法。

本文是一篇发表在 NeurIPS 2024 上的论文,单位是香港大学、Sea AI Lab、Contextual AI 和俄亥俄州立大学。论文主要探讨了大型语言模型(LLMs)的词表大小对模型性能的影响。

RAG(Retrieval-Augmented Generation)是一种结合信息检索与文本生成的技术,旨在提高大型语言模型(LLM)在回答复杂查询时的表现。它通过检索相关的上下文信息来增强生成答案的质量和准确性。解读RAG测评:关键指标与应用分析