里程碑时刻!100B扩散语言模型跑出892 Tokens /秒,AI的另一条路走通了
里程碑时刻!100B扩散语言模型跑出892 Tokens /秒,AI的另一条路走通了扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。
来自主题: AI技术研报
9616 点击 2026-02-11 15:26
 搜索
搜索
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。

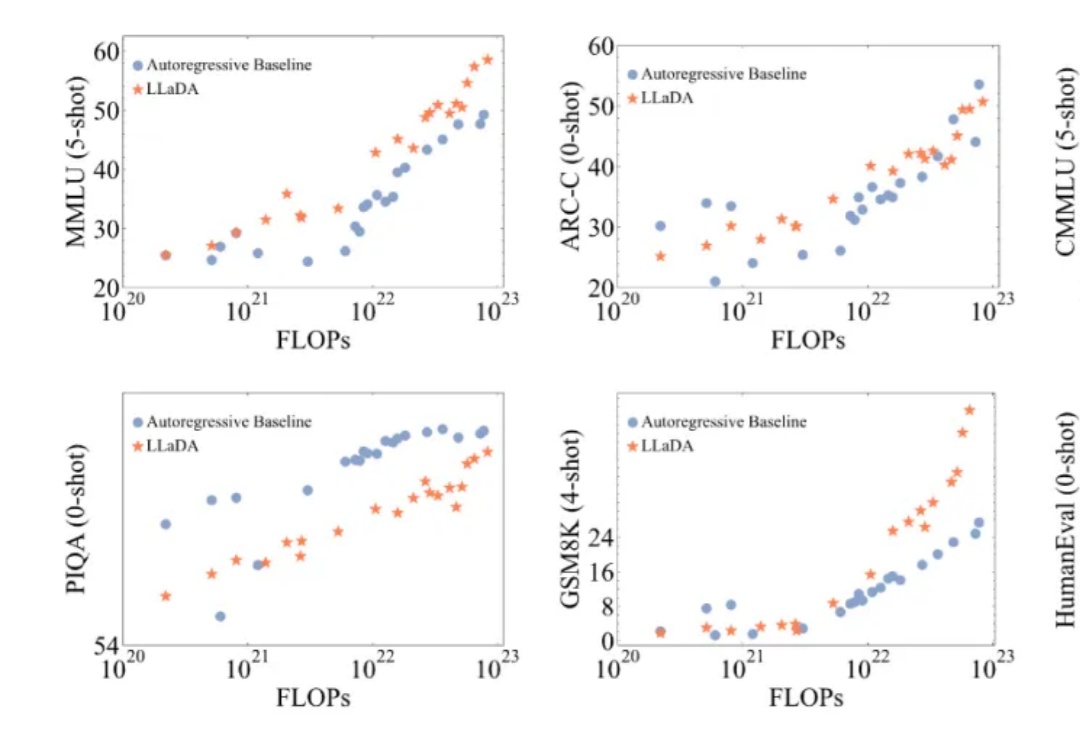
挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。
本文介绍的工作由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。朱峰琪、王榕甄、聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。

当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
用扩散模型替代自回归,大模型的逆诅咒有解了!
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。