新开源之王来了!1320亿参数,逻辑数理全面打赢Grok,还比Llama2-70B快1倍
新开源之王来了!1320亿参数,逻辑数理全面打赢Grok,还比Llama2-70B快1倍“最强”开源大模型之争,又有新王入局:
来自主题: AI技术研报
7347 点击 2024-03-29 11:33
 搜索
搜索
“最强”开源大模型之争,又有新王入局:

参照SuperCLUE(中文通用大模型综合性测评基准)框架专门定制了1000道题目集,一一测试了ChatGPT4、 智谱chatGLM-4、Baichuan2-Turbo、百度ERNIE-Bot 4.0、Yi-34B-chat、llama 2等模型在保险业务上的表现。
这两天,Groq惊艳亮相。它以号称“性价比高英伟达100倍”的芯片,实现每秒500tokens大模型生成,感受不到任何延迟。外加谷歌TPU团队这样一个高精尖人才Buff,让不少人直呼:英伟达要被碾压了……

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

2B性能小钢炮来了!刚刚,面壁智能重磅开源了旗舰级端侧多模态模型MiniCPM,2B就能赶超Mistral-7B,还能越级比肩Llama2-13B。成本更是低到炸裂,170万tokens成本仅为1元!

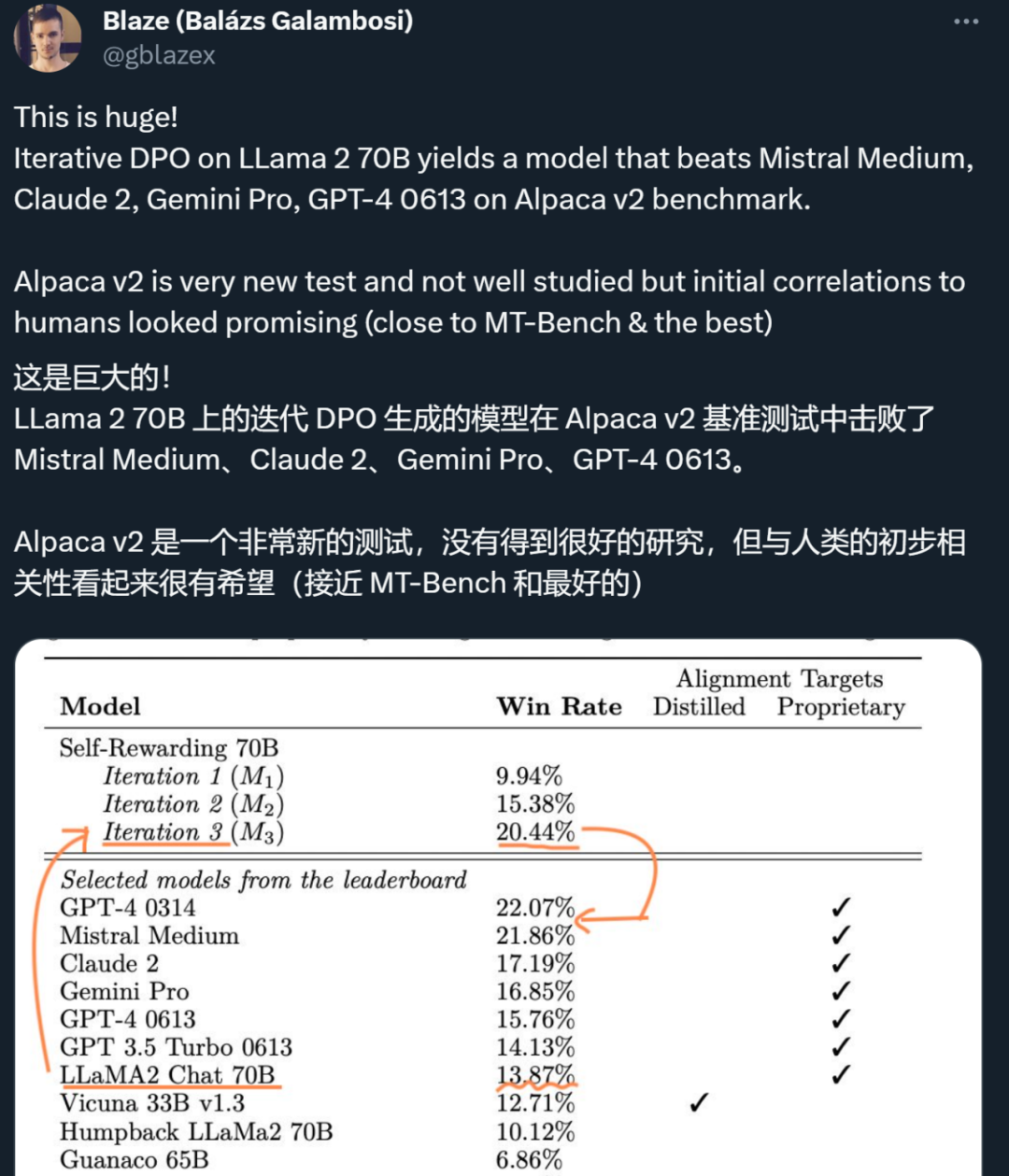
AI训AI必将成为一大趋势。Meta和NYU团队提出让大模型「自我奖励」的方法,让Llama2一举击败GPT-4 0613、Claude 2、Gemini Pro领先模型。
人工智能的反馈(AIF)要代替 RLHF 了?

随着技术的不断发展,各种AI模型框架也越来越多,管理和整合多个模型、服务提供商和密钥可能会变得复杂。幸运的是,而今有一款名为“AI 网关”的开源项目可以帮助简化这一过程。

无需微调,只要四行代码就能让大模型窗口长度暴增,最高可增加3倍!而且是“即插即用”,理论上可以适配任意大模型,目前已在Mistral和Llama2上试验成功。

混合专家模型(MoE)成为最近关注的热点。