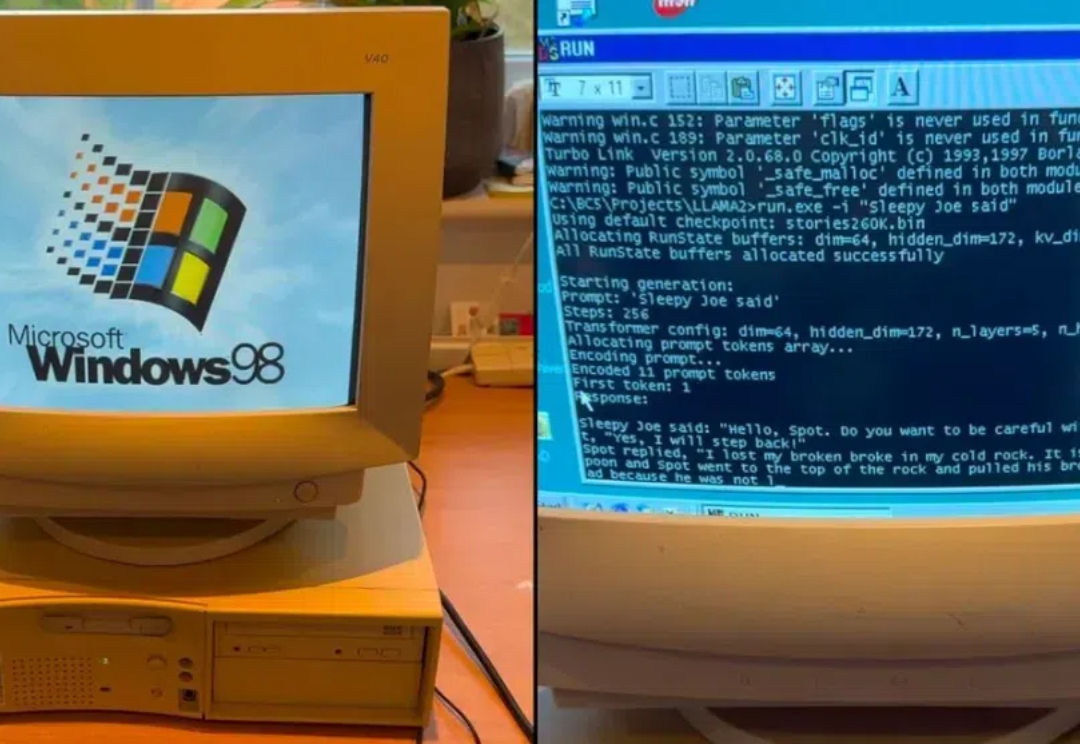
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98
26年前老年机跑Llama2,每秒39个token:你的AI PC,也可以是Windows 98让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。
来自主题: AI资讯
9662 点击 2024-12-30 15:15
 搜索
搜索
让 Llama 2 在 Windows 98 奔腾 2(Pentium II)机器上运行,不但成功了,输出达到 39.31 tok / 秒。
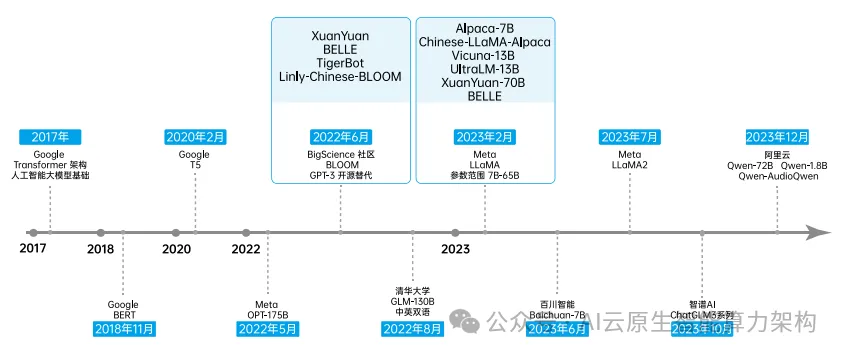
随着开源技术占据各大新兴领域的技术路线,其不断丰富人工智能领域的应用场景。 2023年,Meta 相继发布 Llama 和 Llama2,很快成为广受欢迎的开源大模型,也成为许多模型的基座模型。
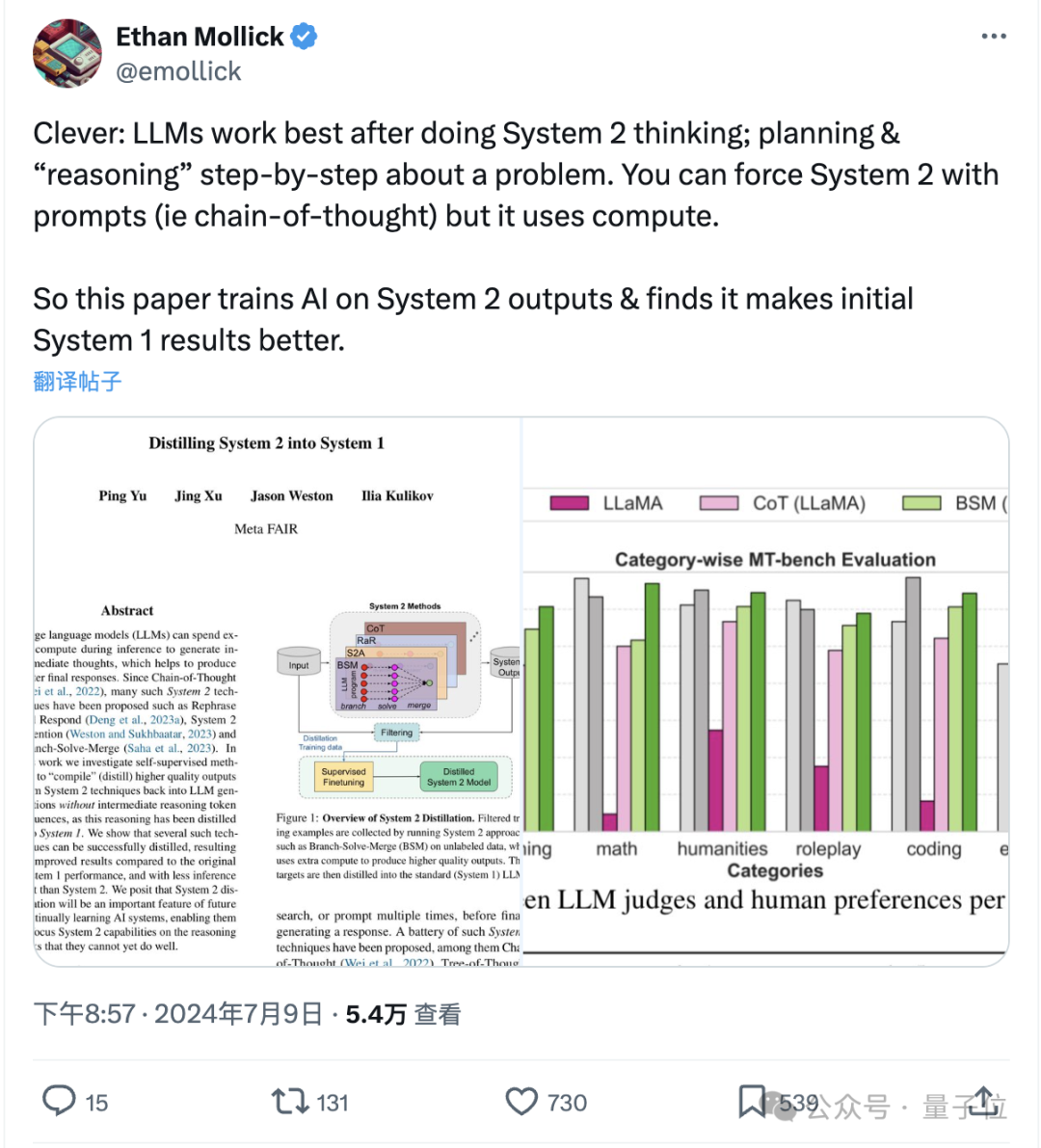
《思考快与慢》中人类的两种思考方式,属实是被Meta给玩明白了。

本周国内最受关注的AI盛事,今日启幕。 活动规格之高,没有哪个关心AI技术发展的人能不为之吸引—— Sora团队负责人Aditya Ramesh与DiT作者谢赛宁同台交流,李开复与张亚勤炉边对话,Llama2/3作者Thomas Scialom,王小川、杨植麟等最受关注AI创业者……也都现场亮相。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。
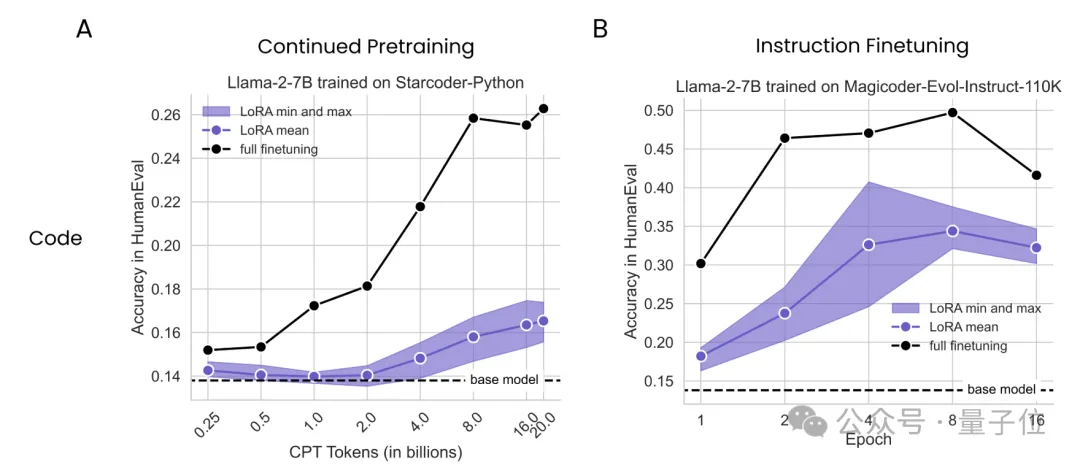
大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。
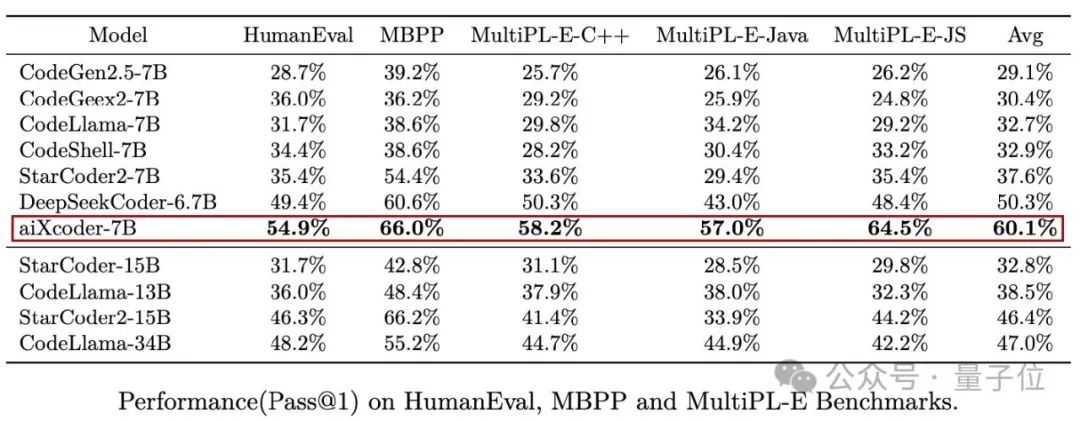
来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
大模型厂商在上下文长度上卷的不可开交之际,一项最新研究泼来了一盆冷水——Claude背后厂商Anthropic发现,随着窗口长度的不断增加,大模型的“越狱”现象开始死灰复燃。无论是闭源的GPT-4和Claude 2,还是开源的Llama2和Mistral,都未能幸免。