全图与切片并非等价?LLaVA-UHD-v3揭示差异推出高效全图建模方案
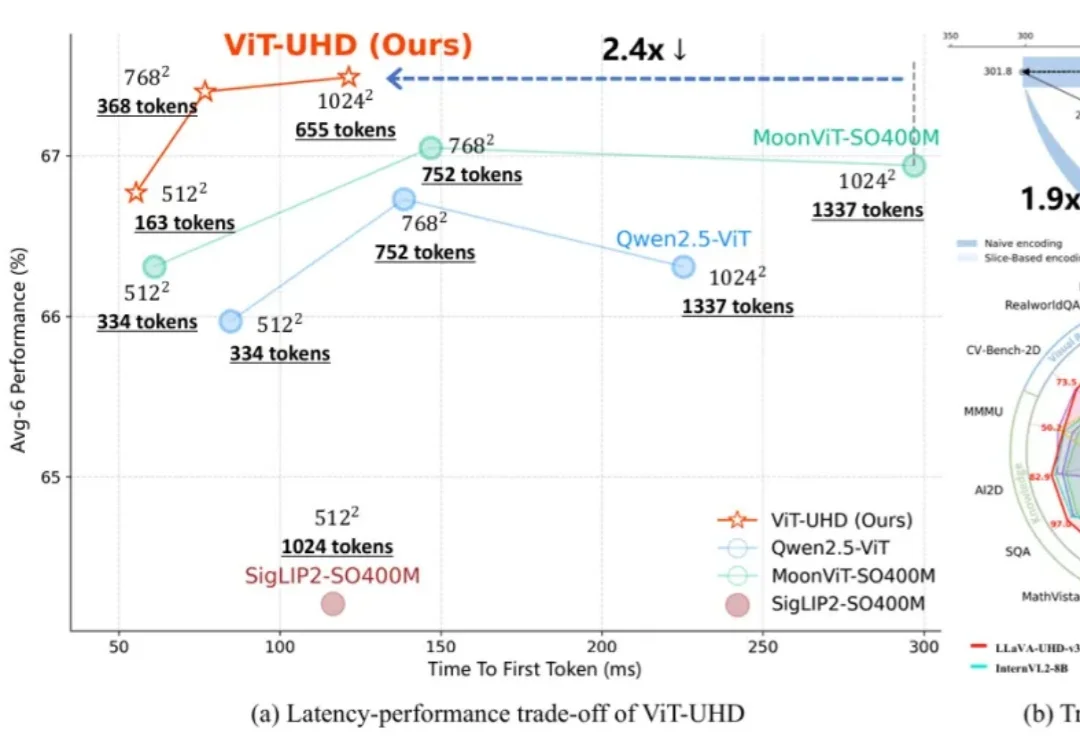
全图与切片并非等价?LLaVA-UHD-v3揭示差异推出高效全图建模方案随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。
来自主题: AI技术研报
10349 点击 2025-12-09 14:38
 搜索
搜索
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。