# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。
然而,主流的视觉编码范式往往难以兼顾性能与效率:基于切片的编码方法虽能降低计算开销,却牺牲了全局上下文感知能力;而全局原生分辨率编码在提升整体性能的同时,又带来了巨大的计算负担。同时,现有的视觉压缩策略与特征提取过程相对独立,难以在编码早期有效控制信息冗余,缺乏一个兼顾细粒度建模与计算效率的统一架构。
针对如何在高清原生分辨率下,保持图像全局理解能力的同时,还能快速推理这一核心问题,来自清华大学、中科院的研究团队正式发布 LLaVA-UHD v3!

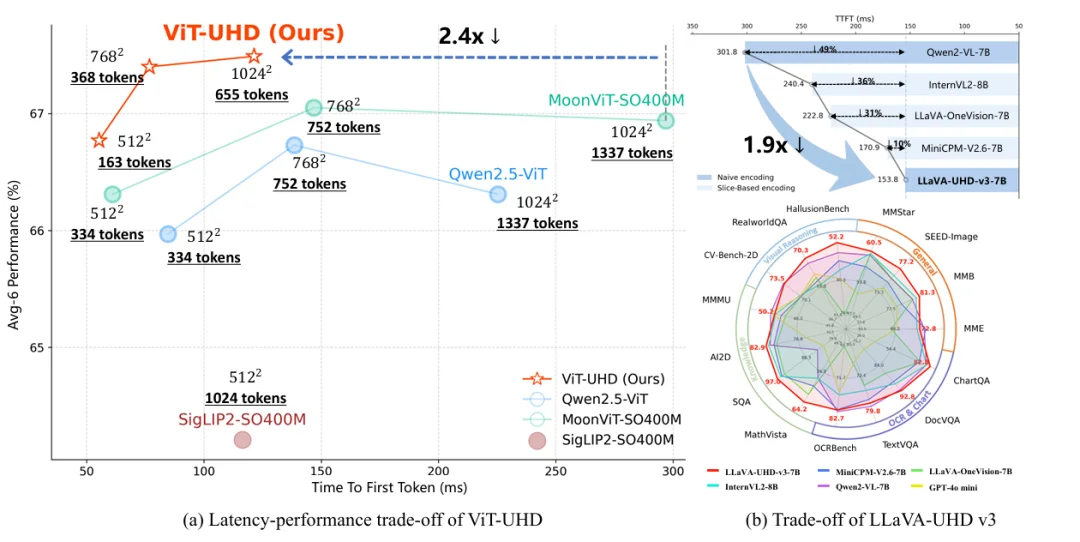
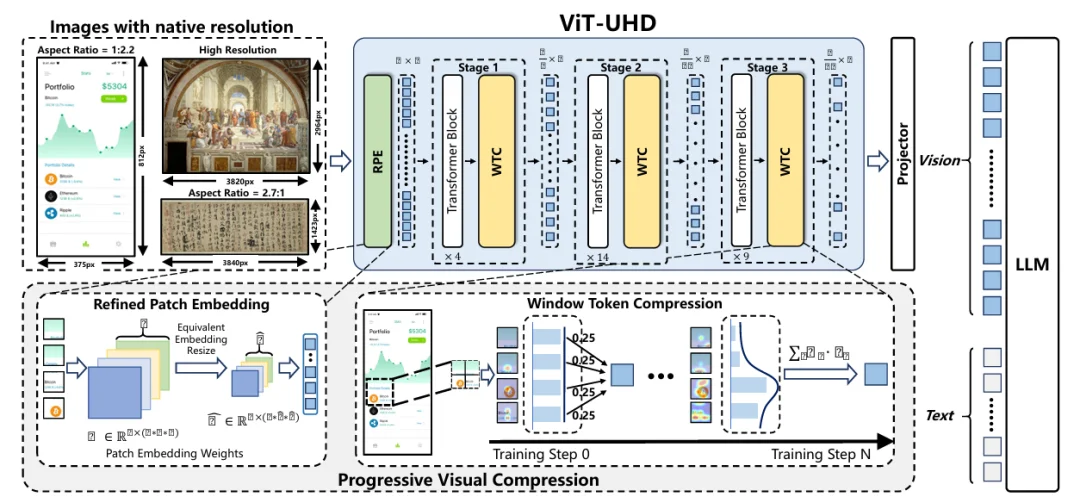
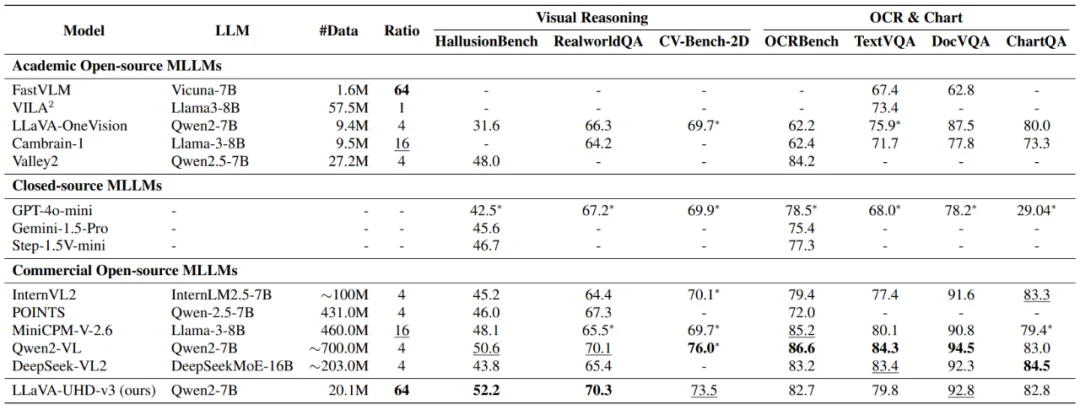
LLaVA-UHD-v3 提出了全新的渐进式视觉压缩框架 ——Progressive Visual Compression(PVC),由 Refined Patch Embedding(RPE) 与 Windowed Token Compression(WTC) 两个核心组件构成。该框架在保持全局语义一致性的前提下,显著减少视觉 Token 数量,从根本上提升原生高分辨率视觉编码的效率。依托 PVC,LLaVA-UHD-v3 在性能上可与 Qwen2-VL 相媲美,同时实现 1.9× 的 TTFT 加速,完整训练仅需 32 张 A100、约 300 小时即可完成。
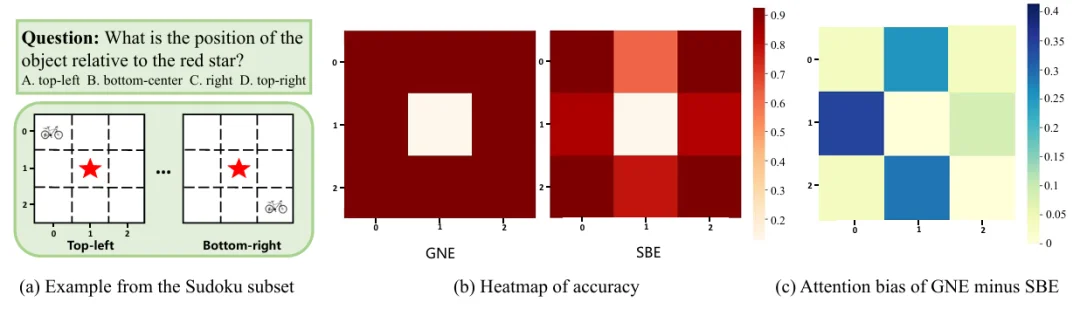
为了公平对比两种主流视觉编码方式 —— 基于切片的编码 (Slice-based Encoding, SBE) 与 全局原生分辨率编码 (Global Native-Resolution Encoding, GNE) —— 团队使用相同模型架构 + 相同训练数据 + 相同评估 protocol。在此基础上,既在通用多模态 benchmark 上测试,也专门构建了一个合成数据集 ShapeGrid 用于空间感知 / 定位能力分析。
在 ShapeGrid (及其 “Sudoku-style” 子集) 上,GNE 相比 SBE 在空间感知 / 定位任务上的表现有明显优势:空间感知能力平均提升约 11.0%。
同时,在通用视觉 - 语言理解任务中,GNE 在语义理解表现上也略优于 SBE(平均提升约 2.1%)。
更重要的是,通过对比注意力热图、激活分布 (attention maps),研究发现 SBE 在空间定位任务中表现出系统性的方向、结构偏差 (例如水平、垂直方向不均衡) —— 也就是说 SBE 的切片机制破坏了图像的空间连续性 (spatial continuity 、geometry),从而削弱了空间理解、定位的可靠性。
因此,该对比实验清晰地表明:尽管 SBE 在效率上有优势,但从语义 + 空间 + 几何一致性 (global context + spatial reasoning) 的角度,GNE 明显更适合需要空间感知、高分辨率理解与推理的任务。
全局原生分辨率编码带来了较高的计算成本,这凸显了迫切需要一种原生且高效的视觉编码范式。因此,团队提出了 LLaVA-UHD v3,一种配备了渐进式视觉压缩(PVC)方法的多模态大模型(MLLM),用于高效的原生分辨率编码。
PVC 架构由两个核心模块组成:
这种 “先细粒度建模 + 再渐进压缩” 的设计,使得 PVC 在兼顾全局语义 + 局部细节的同时,大幅降低计算量。
效率方面,在统一的 LLM(Qwen2-7B)框架下,本文提出的 ViT-UHD 编码器相比 MoonViT 实现了 2.4× 加速,相比 Qwen2.5-ViT 也快 1.9×。将其整合到完整的 MLLM 中后,LLaVA-UHD v3 的 TTFT 相较强大的 Qwen2-VL 降低 49%(约快 1.9×),甚至比以高效著称的切片编码模型 MiniCPM-V2.6 仍然快约 10%。
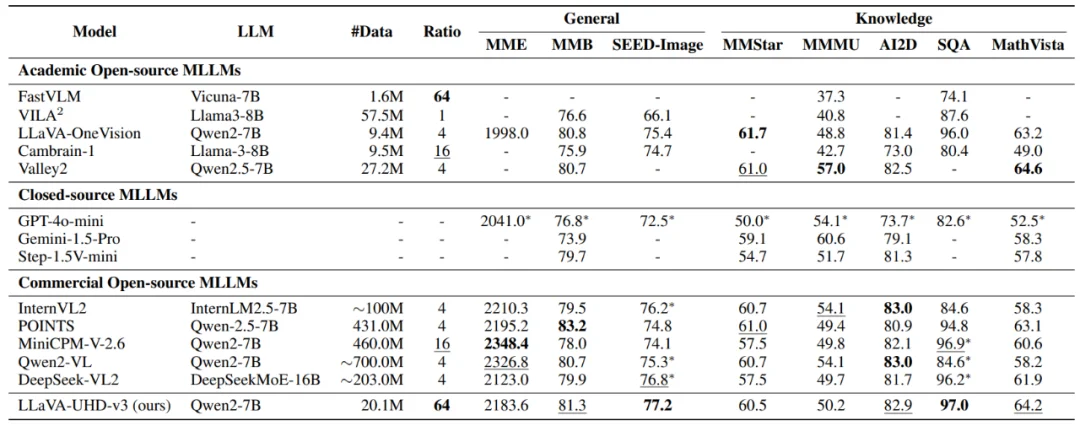
在性能方面,LLaVA-UHD v3 仅使用约 2000 万对图文数据完成训练,远低于 Qwen2-VL(约 7 亿)和 MiniCPM-V-2.6(约 4.6 亿)等商业模型的训练规模。然而,其在多项视觉语言基准中依旧展现出高度竞争力。同时,它实现了 64× 的视觉 Token 压缩率,远超对手(Qwen2-VL 约为 4×,MiniCPM-V2.6 为 16×),但在需要细粒度视觉信息的任务上 —— 包括 HallusionBench(幻觉检测)、CV-Bench(空间推理)以及 OCR&Chart(文字与图表识别)—— 依然取得了与 SOTA 模型相当甚至更优的表现。
这些结果充分验证了 PVC 框架的核心价值:在大幅减少视觉 Token 和推理开销的同时,仍能稳健保留关键的细节感知与全局理解能力,实现真正意义上的 “高效而不降级”。
基于对全图编码与切片编码优劣的深入分析,LLaVA-UHD v3 提出了结合两者优势的渐进式视觉压缩全图编码方案,在保证模型能力的前提下实现了显著的推理效率提升,并展现出良好的迁移与泛化能力,为 MLLM 的高精度原生分辨率建模提供了可行路径。
不过,实验分析表明,缺失了预对齐阶段的 ViT-UHD 性能不佳,这表明引入 PVC 后的视觉编码器能力仍未达到上限:仅靠当前 MLLM 的标准训练流程,很难完全挖掘 ViT 的视觉表征潜力,其学习尚未饱和。此外,随着 Token 数量增大,Transformer 的二次复杂度仍然会带来成本瓶颈。
未来,仍需要探索更适合多模态任务的视觉编码预训练策略,并逐步引入线性复杂度算子替代传统的二次复杂度注意力机制,从而实现真正可扩展的高效多模态建模。
文章来自于“机器之心”,作者 “机器之心”。



